7 Transformer模型构建¶
学习目标¶
- 掌握编码器-解码器结构的实现过程
- 掌握Transformer模型的构建过程
7.1 模型构建介绍¶
通过上面的小节, 我们已经完成了所有组成部分的实现, 接下来就来实现完整的编码器-解码器结构.
Transformer总体架构图:
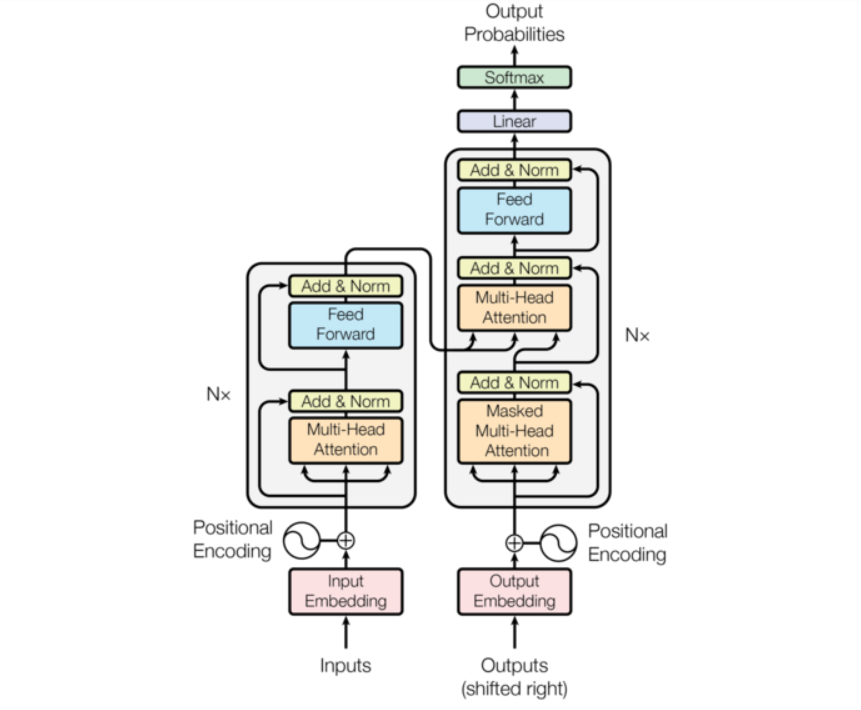
Transformer模型由两部分组成:
- 编码器(Encoder):负责处理输入序列并提取上下文特征。
- 解码器(Decoder):根据编码器的输出和目标序列生成最终的目标序列。
其核心模块包括:
- 嵌入层:将输入/目标序列映射为高维向量。
- 位置编码:为序列引入位置信息。
- 多头注意力机制:捕获序列中不同位置间的依赖关系。
- 前馈全连接网络:进行非线性特征变换。
- 层归一化和残差连接:稳定训练过程。
- 输出层:生成目标序列中的每个词。
Transformer模型的构建流程:
1. 输入处理
-
输入数据准备:
- 将源语言和目标语言的句子转换为整数索引序列。
- 通过词汇表进行词嵌入处理。
-
嵌入层:
-
对输入序列中的每个词索引,查找对应的词向量。
-
结果是形状为 (batch_size, seq_len, d_model)的嵌入张量,
其中:
- batch_size:批量大小。
- seq_len:序列长度。
- d_model:嵌入维度。
-
-
位置编码(Positional Encoding):
- 为输入序列中的每个位置添加位置信息。
- 通过固定正弦函数或可学习的位置嵌入实现。
- 结果是每个时间步都包含了位置信息的嵌入表示。
2. 编码器(Encoder)
编码器由多个堆叠的编码器层组成,每个编码器层包括以下组件:
- 自注意力机制(Self-Attention):
- 计算输入序列中每个位置对其他位置的相关性。
- 生成的上下文表示包含输入序列中的全局依赖关系。
- 残差连接和层归一化:
- 将自注意力的输出与输入相加,保持信息流。
- 通过层归一化稳定训练。
- 前馈全连接网络:
- 对每个时间步的上下文向量单独应用两层全连接网络(带激活函数)。
- 进一步非线性变换输入特征。
- 多层堆叠:
- 编码器由\(N_{\text{enc}}\)个编码器层组成,堆叠后的结果是最终的编码器输出,形状为 (batch_size, seq_len, d_model)。
3. 解码器(Decoder)
解码器也由多个堆叠的解码器层组成,每层包含以下组件:
- 掩码自注意力机制:
- 仅允许目标序列中每个时间步关注它自身及之前的时间步。
- 避免泄漏未来时间步的信息。
- 编码器-解码器注意力机制:
- 将目标序列的上下文表示与编码器的输出进行交互。
- 捕获目标序列与源序列之间的对齐关系。
- 残差连接和层归一化:
- 同样为解码器的每个子层添加残差连接和层归一化,确保梯度稳定。
- 前馈全连接网络:
- 通过两层全连接网络对解码器的上下文表示进一步变换。
- 多层堆叠:
- 解码器由\(N_{\text{dec}}\)个解码器层组成,堆叠后生成解码器的最终输出,形状为 (batch_size, seq_len, d_model)。
4. 输出层
- 线性层:
- 将解码器最后一层的输出投影到目标词汇表的大小。
- 输出 \(logits\),形状为 (batch_size, seq_len, tgt_vocab_size)。
- Softmax 层:
- 对 \(logits\) 应用 \(softmax\) 激活函数,将其转换为概率分布。
- 每个时间步的输出表示目标词汇表中每个词的概率。
- 生成目标序列:
- 在训练阶段,利用真实目标序列进行监督学习。
- 在推断阶段,通过贪心搜索或集束搜索生成完整的目标序列。
7.2 编码器-解码器结构的代码实现¶
EncoderDecoder函数完成编码解码的子任务,就是把编码和解码的流程进行封装实现。
Python
# 编码解码内部函数类 EncoderDecoder 实现分析
# init函数 (self, encoder, decoder, source_embed, target_embed, generator)
# 5个成员属性赋值 encoder 编码器对象 decoder 解码器对象 source_embed source端词嵌入层对象
# target_embed target端词嵌入层对象 generator 输出层对象
# forward函数 (self, source, target, source_mask, target_mask)
# 1 编码 s.encoder(self.src_embed(source), source_mask)
# 2 解码 s.decoder(self.tgt_embed(target), memory, source_mask, target_mask)
# 3 输出 s.generator()
# 使用EncoderDecoder类来实现编码器-解码器结构
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, source_embed, target_embed, generator):
# 初始化函数中有5个参数, 分别是编码器对象, 解码器对象, 源数据嵌入函数, 目标数据嵌入函数, 以及输出部分的类别生成器对象
super(EncoderDecoder, self).__init__()
# 将参数传入到类中
self.encoder = encoder
self.decoder = decoder
# 编码器/解码器输入层对象 由词嵌入对象+位置编码对象组成
# 后续代码中使用 nn.Sequential()类将词嵌入对象+位置编码对象顺序合并到一起, 顺序执行
self.src_embed = source_embed
self.tgt_embed = target_embed
self.generator = generator
def forward(self, source, target, source_mask, target_mask):
# 在forward函数中,有四个参数, source代表源数据, target代表目标数据, source_mask和target_mask代表对应的掩码张量
# 编码器编码, 得到语义张量c
memory = self.encoder(self.src_embed(source), source_mask)
# 解码器解码, 得到预测序列语义张量表示
output = self.decoder(self.tgt_embed(target), memory, source_mask, target_mask)
# 输出层预测, 得到概率表示
output = self.generator(output)
return output
7.3 Tansformer模型构建过程的代码实现¶
make_model函数初始化一个一个组件对象(轮子对象),调用EncoderDecoder()函数
Python
# make_model函数实现思路分析
# 函数原型 (source_vocab, target_vocab, N=6, d_model=512, d_ff=2048, head=8, dropout_p=0.1)
# 实例化多头注意力层对象 attn
# 实例化前馈全连接对象ff
# 实例化位置编码器对象position
# 构建 EncoderDecoder对象(Encoder对象, Decoder对象,
# source端输入部分nn.Sequential(),
# target端输入部分nn.Sequential(),
# 线性层输出Generator)
# 对模型参数初始化 nn.init.xavier_uniform_(p)
# 注意使用 c = copy.deepcopy
# 返回model
def make_model(source_vocab, target_vocab, N=6,
d_model=512, d_ff=2048, head=8, dropout_p=0.1):
c = copy.deepcopy
# 实例化多头注意力层对象
attn = MultiHeadedAttention(head=head, embedding_dim=512, dropout_p=dropout_p)
# 实例化前馈全连接对象ff
ff = PositionwiseFeedForward(d_model=d_model, d_ff=d_ff, dropout_p=dropout_p)
# 实例化 位置编码器对象position
position = PositionalEncoding(d_model=d_model, dropout_p=dropout_p)
# 构建 EncoderDecoder对象
model = EncoderDecoder(
# 编码器对象
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout_p), N),
# 解码器对象
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout_p), N),
# 词嵌入层 位置编码器层容器
# nn.Sequential是一个容器模块,按照传入的顺序执行子模块。
# 它简化了前向传播的定义,无需手动编写forward方法。
nn.Sequential(Embeddings(source_vocab, d_model), c(position)),
# 词嵌入层 位置编码器层容器
nn.Sequential(Embeddings(target_vocab, d_model), c(position)),
# 输出层对象
Generator(d_model, target_vocab))
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model
函数调用:
Python
def dm_test_make_model():
source_vocab = 512
target_vocab = 512
N = 6
model = make_model(source_vocab, target_vocab,
N=N, d_model=512, d_ff=2048, head=8, dropout_p=0.1)
print(model)
# 获取模型的encoder部分
# print('model.encoder--->', model.encoder)
# 获取模型encoder部分第1层子层
# print('model.encoder.layers[0]--->', model.encoder.layers[0])
# 假设源数据与目标数据相同, 实际中并不相同
source = target = torch.LongTensor([[1, 2, 3, 8], [3, 4, 1, 8]])
# 编码器-解码器多头注意力子层填充掩码
source_mask = (source != 0).type(torch.uint8).unsqueeze(1).unsqueeze(2)
# 解码器多头自注意力填充掩码
target_padding_mask = (target != 0).type(torch.uint8).unsqueeze(1).unsqueeze(2)
# 解码器多头自注意力因果掩码
target_causal_mask = torch.tril(torch.ones(size=(4, 4))).type(torch.uint8).unsqueeze(0).unsqueeze(0)
# 解码器多头自注意力子层掩码
target_mask = target_padding_mask & target_causal_mask
mydata = model(source, target, source_mask, target_mask)
print('mydata.shape--->', mydata.shape)
print('mydata--->', mydata)
if __name__ == '__main__':
dm_test_make_model()
输出结果:
Python
EncoderDecoder(
(encoder): Encoder(
(layers): ModuleList(
(0-5): 6 x EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0-3): 4 x Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w1): Linear(in_features=512, out_features=2048, bias=True)
(w2): Linear(in_features=2048, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0-1): 2 x SublayerConnection(
(norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNorm()
)
(decoder): Decoder(
(layers): ModuleList(
(0-5): 6 x DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0-3): 4 x Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0-3): 4 x Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionwiseFeedForward(
(w1): Linear(in_features=512, out_features=2048, bias=True)
(w2): Linear(in_features=2048, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0-2): 3 x SublayerConnection(
(norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
)
(src_embed): Sequential(
(0): Embeddings(
(lut): Embedding(512, 512)
)
(1): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(tgt_embed): Sequential(
(0): Embeddings(
(lut): Embedding(512, 512)
)
(1): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(generator): Generator(
(project): Linear(in_features=512, out_features=512, bias=True)
)
)
mydata.shape---> torch.Size([2, 4, 512])
mydata---> tensor([[[-5.5095, -5.6470, -7.5050, ..., -7.3159, -7.8960, -6.1012],
[-7.2478, -6.7675, -8.7196, ..., -7.1205, -7.0615, -6.0903],
[-6.0191, -6.2244, -6.6764, ..., -7.2188, -7.9671, -6.8258],
[-6.5701, -6.8344, -7.3222, ..., -7.1449, -7.0541, -6.1872]],
[[-5.7291, -5.2186, -7.5897, ..., -7.2993, -6.5601, -6.3607],
[-6.5074, -5.9708, -8.2261, ..., -7.4552, -6.9460, -6.9577],
[-6.5942, -6.0005, -7.6142, ..., -7.2079, -7.2040, -6.0267],
[-6.4325, -6.4567, -8.2288, ..., -6.3692, -7.0105, -5.6366]]],
grad_fn=<LogSoftmaxBackward0>)
7.4 小结¶
- 实现编码器-解码器结构的类: EncoderDecoder
- 类的初始化函数传入5个参数, 分别是编码器对象, 解码器对象, 源数据嵌入函数, 目标数据嵌入函数, 以及输出部分的类别生成器对象
- 类中共实现三个函数, forward, encode, decode
- forward是主要逻辑函数, 有四个参数, source代表源数据, target代表目标数据, source_mask和target_mask代表对应的掩码张量
- encode是编码函数, 以source和source_mask为参数
- decode是解码函数, 以memory即编码器的输出, source_mask, target, target_mask为参数
- 实现模型构建函数: make_model
- 有7个参数,分别是源数据特征(词汇)总数,目标数据特征(词汇)总数,编码器和解码器堆叠数,词向量映射维度,前馈全连接网络中变换矩阵的维度,多头注意力结构中的多头数,以及置零比率dropout_p
- 该函数最后返回一个构建好的模型对象