6 RNN案例-seq2seq英译法¶
学习目标¶
- 更深一步了解seq2seq模型架构和翻译数据集
- 掌握使用基于GRU的seq2seq模型架构实现翻译的过程
- 掌握Attention机制在解码器端的实现过程
6.1 seq2seq模型¶
Seq2Seq(Sequence-to-Sequence)模型是一种用于处理序列转换问题的深度学习模型,广泛应用于机器翻译、文本摘要、对话系统、语音识别等领域。Seq2Seq模型的核心思想是通过一个编码器(Encoder)将输入序列编码为一个固定长度的上下文向量(Context Vector),然后通过一个解码器(Decoder)基于该上下文向量生成输出序列。
6.1.1 基本结构¶
seq2seq模型架构包括三部分,分别是encoder(编码器)、decoder(解码器)、中间语义张量c。其中编码器和解码器的内部实现都使用了GRU模型。
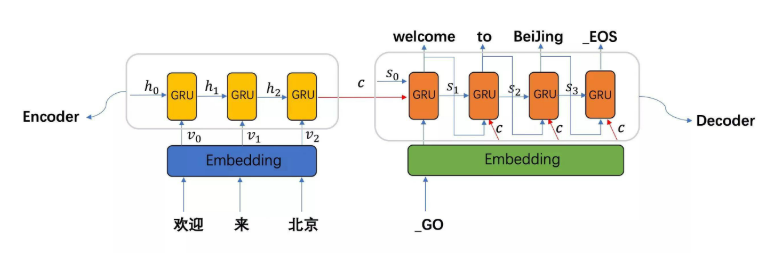
图中表示的是一个中文到英文的翻译:欢迎 来 北京 → welcome to BeiJing。
编码器 (Encoder):
- 将输入序列编码成一个固定长度的上下文向量c (context vector)。这个上下文向量试图捕捉整个输入序列的关键信息。
- 编码器通常使用循环神经网络(RNN),如LSTM或GRU,或者是Transformer模型来实现。
- 输入序列可以是文本、语音信号等。
- 编码器的目标是将变长的输入序列转换为固定长度的向量表示(中间语义张量c)。
- 中间语义张量c=所有时间步的输出组合结果=output。
解码器 (Decoder):
- 将编码器生成的上下文向量c作为输入,并生成目标序列。
- 解码器通常使用循环神经网络(RNN),如LSTM或GRU,或者是Transformer模型来实现。
- 输出序列可以是文本、语音信号等。
- 解码器的目标是将固定长度的向量表示(中间语义张量c)转换为变长的输出序列。
- 解码器通常是自回归形式,即在生成下一个输出(预测y)时需要依赖于之前生成的输出。
6.1.2 工作流程¶
编码阶段:
-
输入序列被逐个输入到编码器中。
-
编码器使用循环神经网络(RNN)或Transformer模型处理输入序列中的每一个元素,并更新隐藏状态。
-
编码器所有时间步的隐藏状态组合被用来生成上下文向量(中间语义张量c)。
-
数学表示
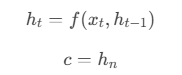
- \(h_t\) 是编码器在时间步\(t\)的隐藏状态。
- \(f\) 是编码器的循环神经网络(如 RNN、LSTM 或 GRU)。
- \(c\) 是上下文向量,通常是编码器的所有隐藏状态\(h_n\)。
解码阶段:
-
解码器将编码器生成的上下文向量(中间语义张量c)作为初始输入。
-
解码器的初始隐藏状态通常设置为编码器的最后一个隐藏状态\(h_n\)。
-
解码器使用循环神经网络(RNN)或Transformer模型,并使用之前生成的输出作为输入,逐个生成目标序列的输出。
-
解码器会重复执行此步骤直到生成一个特殊的结束符(例如
) ,或者达到预先设定的输出序列长度。 -
数学表示
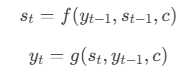
- \(s_t\) 是解码器在时间步\(t\)的隐藏状态。
- \(f\) 是解码器的循环神经网络(如 RNN、LSTM或GRU)。
- \(g\) 是输出函数,通常是一个全连接层(线性层+softmax层)。
6.1.3 局限性¶
- 信息瓶颈:编码器需要将整个输入序列的信息压缩到一个固定长度的上下文向量中,容易导致信息丢失。
- 长序列问题:对于长序列,模型难以捕捉远距离依赖关系,性能显著下降。
接下来我们通过英译法的案例来讲解seq2seq设计与实现。
6.2 数据集介绍¶
-
data/eng-fra-v2.txt 是我们案例使用的数据集
-
左半部分是英文,右半部分是法文
Pythoni am from brazil . je viens du bresil . i am from france . je viens de france . i am from russia . je viens de russie . i am frying fish . je fais frire du poisson . i am not kidding . je ne blague pas . i am on duty now . maintenant je suis en service . i am on duty now . je suis actuellement en service . i am only joking . je ne fais que blaguer . i am out of time . je suis a court de temps . i am out of work . je suis au chomage . i am out of work . je suis sans travail . i am paid weekly . je suis payee a la semaine . i am pretty sure . je suis relativement sur . i am truly sorry . je suis vraiment desole . i am truly sorry . je suis vraiment desolee .
6.3 案例实现步骤¶
基于GRU的seq2seq模型架构实现翻译的过程:
- 第一步: 导入工具包和工具函数
- 第二步: 对持久化文件中的数据进行处理, 以满足模型训练要求
- 第三步: 构建基于GRU的编码器和解码器
- 第四步: 构建模型训练函数, 并进行训练
- 第五步: 构建模型评估函数, 并进行测试以及Attention效果分析
6.3.1 导入工具包和工具函数¶
# 用于正则表达式
import re
# 用于构建网络结构和函数的torch工具包
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# torch中预定义的优化方法工具包
import torch.optim as optim
import time
# 用于随机生成数据
import random
import numpy as np
import matplotlib.pyplot as plt
# 设备选择, 我们可以选择在cuda或者cpu上运行你的代码
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 起始标志 SOS->Start Of Sequence
SOS_token = 0
# 结束标志 EOS->End Of Sequence
EOS_token = 1
# 最大句子长度不能超过10个(包含标点),用于设置每个句子样本的中间语义张量c长度都为10。
MAX_LENGTH = 10
# 数据文件路径
data_path = "./data/eng-fra-v2.txt"
# 文本清洗工具函数
def normalizeString(s: str):
"""字符串规范化函数, 参数s代表传入的字符串"""
s = s.lower().strip()
# 在.!?前加一个空格, 即用 “空格 + 原标点” 替换原标点。
# \1 代表 捕获的标点符号,即 ., !, ? 之一。
s = re.sub(r"([.!?])", r" \1", s)
# 用一个空格替换原标点,意味着 标点符号被完全去掉,只留下空格。
# s = re.sub(r"([.!?])", r" ", s)
# 使用正则表达式将字符串中 不是 至少1个小写字母和正常标点的都替换成空格
s = re.sub(r"[^a-z.!?]+", r" ", s)
return s
6.3.2 数据预处理¶
对持久化文件中数据进行处理, 以满足模型训练要求
6.3.2.1 清洗文本和构建文本字典¶
-
清洗文本和构建文本字典思路分析
Python# my_getdata() 清洗文本构建字典思路分析 # 1 按行读文件 open().read().strip().split(\n) my_lines # 2 按行清洗文本 构建语言对 my_pairs[] tmppair[] # 2-1格式 [['英文', '法文'], ['英文', '法文'], ['英文', '法文'], ['英文', '法文']....] # 2-2调用清洗文本工具函数normalizeString(s) # 3 遍历语言对 构建英语单词字典 法语单词字典 my_pairs->pair->pair[0].split(' ') pair[1].split(' ')->word # 3-1 english_word2index english_word_n french_word2index french_word_n # 其中 english_word2index = {0: "SOS", 1: "EOS"} english_word_n=2 # 3-2 english_index2word french_index2word # 4 返回数据的7个结果 # english_word2index, english_index2word, english_word_n, # french_word2index, french_index2word, french_word_n, my_pairs -
代码实现
def my_getdata():
# 1 按行读文件 open().read().strip().split(\n)
with open(data_path, "r", encoding="utf-8") as f:
my_lines = f.read().strip().split("\n")
print("my_lines--->", len(my_lines))
# 2 按行清洗文本 构建语言对 my_pairs
# 格式 [['英文句子', '法文句子'], ['英文句子', '法文句子'], ['英文句子', '法文句子'], ... ]
tmp_pair, my_pairs = [], []
for l in my_lines:
for s in l.split("\t"):
tmp_pair.append(normalizeString(s))
my_pairs.append(tmp_pair)
# 清空tmp_pair, 存储下一个句子的英语和法语的句子对
tmp_pair = []
# my_pairs = [[normalizeString(s) for s in l.split('\t')] for l in my_lines]
# print('my_pairs--->', my_pairs)
print("len(my_pairs)--->", len(my_pairs))
# 打印前4条数据
print(my_pairs[:4])
# 打印第8000条的英文 法文数据
print("my_pairs[8000][0]--->", my_pairs[8000][0])
print("my_pairs[8000][1]--->", my_pairs[8000][1])
# 3 遍历语言对 构建英语单词字典 法语单词字典
# 3-1 english_word2index english_word_n french_word2index french_word_n
# SOS->Start Of Sequence
# EOS->End Of Sequence
english_word2index = {"SOS": 0, "EOS": 1}
# 第三个单词的下标值从2开始
english_word_n = 2
french_word2index = {"SOS": 0, "EOS": 1}
french_word_n = 2
# 遍历语言对 获取英语单词字典 法语单词字典
# {单词1:下标1, 单词2:下标2, ...}
for pair in my_pairs:
for word in pair[0].split(" "):
if word not in english_word2index:
english_word2index[word] = english_word_n
# 更新下一个单词的下标值
english_word_n += 1
for word in pair[1].split(" "):
if word not in french_word2index:
french_word2index[word] = french_word_n
french_word_n += 1
# 3-2 english_index2word french_index2word
# # {下标1:单词1, 下标2:单词2, ...}
english_index2word = {v: k for k, v in english_word2index.items()}
french_index2word = {v: k for k, v in french_word2index.items()}
print("len(english_word2index)-->", len(english_word2index))
print("len(french_word2index)-->", len(french_word2index))
print("english_word_n--->", english_word_n, "french_word_n-->", french_word_n)
return (
english_word2index,
english_index2word,
english_word_n,
french_word2index,
french_index2word,
french_word_n,
my_pairs,
)
if __name__ == "__main__":
# 获取英语单词字典 法语单词字典 语言对列表my_pairs
(
english_word2index,
english_index2word,
english_word_n,
french_word2index,
french_index2word,
french_word_n,
my_pairs,
) = my_getdata()
输出结果:
my_lines---> 63594
len(pairs)---> 63594
[['i m .', 'j ai ans .'], ['i m ok .', 'je vais bien .'], ['i m ok .', 'ca va .'], ['i m fat .', 'je suis gras .']]
my_pairs[8000][0]---> they re in the science lab .
my_pairs[8000][1]---> elles sont dans le laboratoire de sciences .
len(english_word2index)--> 2803
len(french_word2index)--> 4345
english_word_n---> 2803 french_word_n--> 4345
6.3.2.2 构建数据源对象¶
# 原始数据 -> 数据源MyPairsDataset --> 数据迭代器DataLoader
# 构造数据源 MyPairsDataset,把语料xy 文本数值化 再转成tensor_x tensor_y
# 1 __init__(self, my_pairs)函数 设置self.my_pairs 条目数self.sample_len
# 2 __len__(self)函数 获取样本条数
# 3 __getitem__(self, index)函数 获取第几条样本数据
# 按索引 获取数据样本 x y
# 样本x 文本数值化 word2id x.append(EOS_token)
# 样本y 文本数值化 word2id y.append(EOS_token)
# 返回tensor_x, tensor_y
class MyPairsDataset(Dataset):
def __init__(self, my_pairs, english_word2index, french_word2index):
# 样本x
self.my_pairs = my_pairs
self.english_word2index = english_word2index
self.french_word2index = french_word2index
# 样本条目数
self.sample_len = len(my_pairs)
# 获取样本条数
def __len__(self):
return self.sample_len
# 获取第几条 样本数据
def __getitem__(self, index):
# 对index异常值进行修正 [0, self.sample_len-1]
index = min(max(index, 0), self.sample_len - 1)
# 按索引获取 数据样本 x y
x = self.my_pairs[index][0] # 英文句子
y = self.my_pairs[index][1] # 法文句子
# 样本x 文本数值化
x = [self.english_word2index[word] for word in x.split(" ")]
x.append(EOS_token)
tensor_x = torch.tensor(x, dtype=torch.long, device=device)
# print('tensor_x.shape===>', tensor_x.shape, tensor_x)
# 样本y 文本数值化
y = [self.french_word2index[word] for word in y.split(" ")]
y.append(EOS_token)
tensor_y = torch.tensor(y, dtype=torch.long, device=device)
# 注意 tensor_x tensor_y都是一维数组,通过DataLoader拿出的数据是二维数据
# print('tensor_y.shape===>', tensor_y.shape, tensor_y)
# 返回结果
return tensor_x, tensor_y
6.3.2.3 构建数据加载器¶
def dm_test_MyPairsDataset():
# 1 调用my_getdata函数获取数据
(
english_word2index,
english_index2word,
english_word_n,
french_word2index,
french_index2word,
french_word_n,
my_pairs,
) = my_getdata()
# 2 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs, english_word2index, french_word2index)
# 3 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
for i, (x, y) in enumerate(mydataloader):
print("x.shape", x.shape, x)
print("y.shape", y.shape, y)
break
if __name__ == "__main__":
dm_test_MyPairsDataset()
输出结果:
x.shape torch.Size([1, 6]) tensor([[14, 15, 1140, 306, 4, 1]], device='cuda:0')
y.shape torch.Size([1, 6]) tensor([[24, 115, 2045, 527, 5, 1]], device='cuda:0')
6.3.3 构建基于GRU的编码器和解码器¶
6.3.3.1 构建基于GRU的编码器¶
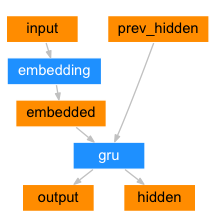
-
编码器结构图:
-
实现思路分析
Python# EncoderRNN类 实现思路分析: # 1 init函数 定义2个层 self.embedding self.gru (batch_first=True) # def __init__(self, input_size, hidden_size): # 2803 256 # 2 forward(input, hidden)函数,返回output, hidden # 数据经过词嵌入层 数据形状 [1,6] --> [1,6,256] # 数据经过gru层 形状变化 gru([1,6,256],[1,1,256]) --> [1,6,256] [1,1,256] # 3 初始化隐藏层输入数据 inithidden() # 形状 torch.zeros(1, 1, self.hidden_size, device=device) -
代码实现
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
# input_size 编码器 词嵌入层单词数 eg:2803
# hidden_size 编码器 词嵌入层每个单词的特征数 eg 256
super(EncoderRNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
# 实例化nn.Embedding层
self.embedding = nn.Embedding(
num_embeddings=self.input_size, embedding_dim=self.hidden_size
)
# 实例化nn.GRU层 注意参数batch_first=True->(batch_size, seq_len, hidden_size)
self.gru = nn.GRU(
input_size=self.hidden_size, hidden_size=self.hidden_size, batch_first=True
)
def forward(self, input, hidden):
# 数据经过词嵌入层 数据形状 [1,6] --> [1,6,256]
output = self.embedding(input)
# 数据经过gru层 数据形状 gru([1,6,256],[1,1,256]) --> [1,6,256] [1,1,256]
output, hidden = self.gru(output, hidden)
return output, hidden
def inithidden(self):
# 将隐藏层张量初始化成为1x1xself.hidden_size大小的张量
return torch.zeros(size=(1, 1, self.hidden_size), device=device)
调用:
def dm_test_EncoderRNN():
# 调用my_getdata函数获取数据
(
english_word2index,
english_index2word,
english_word_n,
french_word2index,
french_index2word,
french_word_n,
my_pairs,
) = my_getdata()
# 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs, english_word2index, french_word2index)
# 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化模型
input_size = english_word_n
hidden_size = 256
my_encoderrnn = EncoderRNN(input_size, hidden_size).to(device=device)
print("my_encoderrnn模型结构--->", my_encoderrnn)
# 给encode模型喂数据
for i, (x, y) in enumerate(mydataloader):
print("x.shape", x.shape, x)
print("y.shape", y.shape, y)
# 一次性的送数据
hidden = my_encoderrnn.inithidden()
# encode_output_c: 未加attention的中间语义张量c
encode_output_c, hidden = my_encoderrnn(x, hidden)
print("encode_output_c.shape--->", encode_output_c.shape, encode_output_c)
break
if __name__ == "__main__":
dm_test_EncoderRNN()
输出结果:
x.shape torch.Size([1, 5]) tensor([[221, 78, 940, 4, 1]], device='cuda:0')
y.shape torch.Size([1, 5]) tensor([[348, 349, 1710, 5, 1]], device='cuda:0')
encode_output_c.shape---> torch.Size([1, 5, 256]) tensor([[[ 0.1810, 0.0139, 0.5656, ..., 0.0184, 0.4561, -0.2775],
[-0.2903, -0.3651, -0.0614, ..., -0.1572, 0.4740, 0.1643],
[ 0.0889, -0.2346, -0.1555, ..., 0.2072, 0.0954, 0.2167],
[-0.1387, 0.2336, -0.3864, ..., 0.3392, 0.2298, 0.1937],
[ 0.1967, -0.2525, -0.2144, ..., 0.2121, 0.2042, 0.4239]]],
device='cuda:0', grad_fn=<CudnnRnnBackward0>)
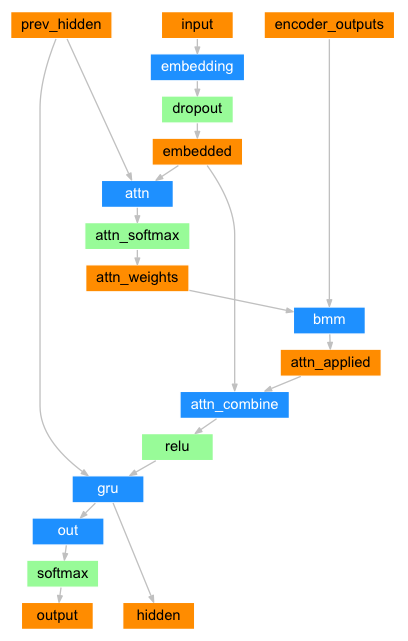
6.3.3.2 构建基于GRU和Attention的解码器¶
解码器负责生成输出序列,而编码器负责对输入序列进行编码。因此,注意力机制的作用是帮助解码器更好地利用编码器的信息。注意力机制加在解码器中,而不是编码器中。
-
解码器结构图:
-
实现思路分析
Python# 构建基于GRU和Attention的解码器 # AttnDecoderRNN 类 实现思路分析: # 1 init函数 定义六个层 # self.embedding self.attn self.attn_combine # self.gru self.out self.softmax=nn.LogSoftmax(dim=-1) # def __init__(self, output_size, hidden_size, dropout_p=0.1, max_length=MAX_LENGTH):: # 4345 256 # 2 forward(input, hidden, encoder_outputs)函数,返回output, hidden # 数据经过词嵌入层 数据形状 [1,1] --> [1,1,256] # 1 求查询张量q的注意力权重分布, attn_weights[1,1,10] # 2 求查询张量q的注意力结果表示 bmm运算, attn_applied[1,1,256] # 3 q 与 attn_applied 融合,经过层attn_combine 按照指定维度输出 output[1,1,256] # 数据经过relu()层 output = F.relu(output) # 数据经过gru层 形状变化 gru([1,1,256],[1,1,256]) --> [1,1,256] [1,1,256] # 返回 # 返回解码器分类output[1,4345],最后隐层张量hidden[1,1,256] 注意力权重张量attn_weights[1,1,10] # 相对传统RNN解码 AttnDecoderRNN类多了注意力机制,需要构建QKV # 1 在init函数中 (self, output_size, hidden_size, dropout_p=0.1, max_length=MAX_LENGTH) # 增加层 self.attn self.attn_combine self.dropout # 2 增加函数 attentionQKV(self, Q, K, V) # 3 函数forward(self, input, hidden, encoder_outputs) # encoder_outputs 每个时间步解码准备qkv 调用attentionQKV # 函数返回值 output, hidden, attn_weights # 4 调用需要准备中间语义张量C encode_output_c -
代码实现
class AttnDecoderRNN(nn.Module):
def __init__(self, output_size, hidden_size, dropout_p=0.1, max_length=MAX_LENGTH):
# output_size 解码器 词嵌入层单词数 eg:4345
# hidden_size 解码器 词嵌入层每个单词的特征数 eg 256
# dropout_p 置零比率,默认0.1,
# max_length 最大长度10
super(AttnDecoderRNN, self).__init__()
self.output_size = output_size
self.hidden_size = hidden_size
self.dropout_p = dropout_p
self.max_length = max_length
# 定义nn.Embedding层 nn.Embedding(4345,256)
self.embedding = nn.Embedding(num_embeddings=self.output_size, embedding_dim=self.hidden_size)
# 定义线性层1:求q的注意力权重分布
# 查询张量Q: 解码器每个时间步的隐藏层输出或者是当前输入的x
# 键张量K: 解码器上一个时间步的隐藏层输出
# self.hidden_size * 2 = q + k
self.attn = nn.Linear(in_features=self.hidden_size * 2, out_features=self.max_length)
# 定义线性层2:q+注意力结果表示融合后,在按照指定维度输出
# 值张量V:编码部分每个时间步输出结果组合而成
# self.hidden_size * 2 = q + v
self.attn_combine = nn.Linear(in_features=self.hidden_size * 2, out_features=self.hidden_size)
# 定义dropout层
self.dropout = nn.Dropout(p=self.dropout_p)
# 定义gru层
self.gru = nn.GRU(input_size=self.hidden_size, hidden_size=self.hidden_size, batch_first=True)
# 定义out层 解码器按照类别进行输出(256,4345)
self.out = nn.Linear(in_features=self.hidden_size, out_features=self.output_size)
# 实例化softomax层 数值归一化 以便分类
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input, hidden, encoder_outputs):
# input代表q [1,1] 二维数据 hidden代表k [1,1,256] encoder_outputs代表v [1,10,256]
# 数据经过词嵌入层
# 数据形状 [1,1] --> [1,1,256]
embedded = self.embedding(input)
# 使用dropout进行随机丢弃,防止过拟合
embedded = self.dropout(embedded)
# 1 求查询张量q的注意力权重分布, attn_weights[1,1,10]
attn_weights = torch.softmax(
self.attn(torch.cat(tensors=(embedded, hidden), dim=-1)), dim=-1)
# 2 求查询张量q的注意力结果表示 bmm运算, attn_applied[1,1,256]
# [1,1,10], [1,10,256] ---> [1,1,256]
attn_applied = torch.bmm(input=attn_weights, mat2=encoder_outputs)
# 3 q 与 attn_applied 融合,[1,1,512]
output = torch.cat(tensors=(embedded, attn_applied), dim=-1)
# 再按照指定维度输出 output[1,1,256], gru层输入形状要求
output = self.attn_combine(output)
# 查询张量q的注意力结果表示 使用relu激活
output = torch.relu(output)
# 查询张量经过gru、softmax进行分类结果输出
# 数据形状[1,1,256],[1,1,256] --> [1,1,256], [1,1,256]
output, hidden = self.gru(output, hidden)
# output经过全连接层 out+softmax层, 全连接层要求输入数据为二维数据
# 数据形状[1,1,256]->[1,256]->[1,4345]
output = self.softmax(self.out(output[:, 0, :]))
# 返回解码器分类output[1,4345],最后隐层张量hidden[1,1,256] 注意力权重张量attn_weights[1,1,10]
return output, hidden, attn_weights
调用:
def dm_test_AttnDecoderRNN():
# 获取数据
(
english_word2index,
english_index2word,
english_word_n,
french_word2index,
french_index2word,
french_word_n,
my_pairs,
) = my_getdata()
# 1 实例化 数据集对象
mypairsdataset = MyPairsDataset(my_pairs, english_word2index, french_word2index)
# 2 实例化 数据加载器对象
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化 编码器my_encoderrnn
my_encoderrnn = EncoderRNN(english_word_n, 256).to(device=device)
# 实例化 解码器DecoderRNN
my_attndecoderrnn = AttnDecoderRNN(french_word_n, 256).to(device=device)
# 3 遍历数据迭代器
for i, (x, y) in enumerate(mydataloader):
# 编码-方法1 一次性给模型送数据
hidden = my_encoderrnn.inithidden()
print("x--->", x.shape, x)
print("y--->", y.shape, y)
# [1, 6, 256], [1, 1, 256]) --> [1, 6, 256][1, 1, 256]
output, hidden = my_encoderrnn(x, hidden)
# print('output-->', output.shape, output)
# print('最后一个时间步取出output[0,-1]-->', output[0, -1].shape, output[0, -1])
# 中间语义张量c
# print('my_encoderrnn.hidden_size--->', my_encoderrnn.hidden_size)
# 初始化全0中间语义张量c
# 每个句子样本的词语数量不一样, 所以初始的中间语义张量c长度不一样
# 用最大长度对所有句子样本的中间语义张量c长度进行长度规范化
# 编码器的输入x最大长度为10, 可能小于10, 其他的用0表示
encode_output_c = torch.zeros(
1, MAX_LENGTH, my_encoderrnn.hidden_size, device=device
)
for idx in range(output.shape[1]):
# 循环中将每个时间步的输出值赋值给中间语义张量C
# encode_output_c->(1, 10, 256)
# output->(1, 句子长度, 256) output[:, idx, :]->所有句子第idx词语的语义向量
# 长度不为10的句子, 其他位置就是全0
encode_output_c[:, idx, :] = output[:, idx, :]
# print("encode_output_c.shape", encode_output_c.shape, encode_output_c)
# 解码-必须一个字符一个字符的解码
for i in range(y.shape[1]):
tmp = y[:, i].reshape(-1, 1)
output, hidden, attn_weights = my_attndecoderrnn(
tmp, hidden, encode_output_c
)
print("解码output.shape", output.shape)
print("解码hidden.shape", hidden.shape)
print("解码attn_weights.shape", attn_weights.shape)
break
if __name__ == "__main__":
dm_test_AttnDecoderRNN()
输出结果:
x---> torch.Size([1, 7]) tensor([[ 2, 16, 108, 1585, 1587, 4, 1]], device='cuda:0')
y---> torch.Size([1, 7]) tensor([[ 6, 2687, 453, 2688, 2689, 5, 1]], device='cuda:0')
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 1, 10])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 1, 10])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 1, 10])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 1, 10])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 1, 10])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 1, 10])
解码output.shape torch.Size([1, 4345])
解码hidden.shape torch.Size([1, 1, 256])
解码attn_weights.shape torch.Size([1, 1, 10])
6.3.4 构建模型训练函数并进行训练¶
6.3.4.1 Teacher Forcing介绍¶
-
概念
Teacher Forcing 是一种在训练序列到序列(Seq2Seq)模型时常用的技术,特别是在解码器(Decoder)的训练过程中。它的核心思想是:在训练时,使用真实的目标序列(Ground Truth)作为解码器的输入,而不是使用解码器自己生成的输出。这种方法可以加速模型的收敛,并提高训练稳定性。在 Seq2Seq 模型中,解码器的任务是基于编码器的输出生成目标序列。在训练过程中,解码器的输入通常包括:
- 上一个时间步的输出 \(y_{t−1}\)。
- 上一个时间步的隐藏状态 \(s_{t−1}\)。
- 上下文向量 \(c_t\)(如果使用了注意力机制)。
如果解码器在上一个时间步生成了错误的输出 \(y_{t−1}\),那么这个错误会传递到下一个时间步,导致误差累积,影响模型的训练效果。
-
作用
- 能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大。
- teacher forcing能够极大的加快模型的收敛速度,令模型训练过程更快更平稳。
-
优点
- 加速收敛:使用真实的目标序列作为输入,可以避免误差累积,加速模型的收敛。
- 提高训练稳定性:解码器的输入是已知的,训练过程更加稳定。
-
缺点
- 训练-测试不一致:在训练时,解码器的输入是真实的目标序列;而在测试时,解码器的输入是它自己生成的输出。这种不一致性可能导致模型在测试时表现不佳。
- 过度依赖真实数据:模型可能过度依赖真实的目标序列,导致泛化能力下降。
-
Teacher Forcing 的改进
- Scheduled Sampling
- 在训练过程中,动态调整Teacher Forcing的比例。例如,初始时使用较高的Teacher Forcing比例,随着训练的进行逐渐降低。
- 这种方法可以缓解训练-测试不一致的问题。
- Curriculum Learning
- 在训练初期,使用较高的Teacher Forcing比例;随着训练的进行,逐渐降低Teacher Forcing的比例。
- 先训练短句子,再逐渐增加长句子,这样可以降低长距离依赖的难度。
- 先使用低难度样本(如高质量标注数据),再逐渐引入更复杂的训练数据。
- 这种方法可以帮助模型逐步适应测试时的条件。
- Scheduled Sampling
6.3.4.2 构建内部迭代训练函数¶
- 模型训练参数
-
实现思路分析
Python# 内部迭代训练函数train_iters # 1 编码 encode_output, encode_hidden = my_encoderrnn(x, encode_hidden) # 数据形状 eg [1,6],[1,1,256] --> [1,6,256],[1,1,256] # 2 解码参数准备和解码 # 解码参数1 固定长度C encoder_outputs_c = torch.zeros(MAX_LENGTH, my_encoderrnn.hidden_size, device=device) # 解码参数2 decode_hidden # 解码参数3 input_y = torch.tensor([[SOS_token]], device=device) # 数据形状数据形状 [1,1],[1,1,256],[1,10,256] ---> [1,4345],[1,1,256],[1,1,10] # output_y, decode_hidden, attn_weight = my_attndecoderrnn(input_y, decode_hidden, encode_output_c) # 计算损失 target_y = y[:, i] # 每个时间步处理 for idx in range(y_len): 处理三者之间关系input_y output_y target_y # 3 训练策略 use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False # teacher_forcing 把样本真实值y作为下一次输入 input_y = y[:, i].reshape(shape=(-1, 1)) # not teacher_forcing 把预测值y作为下一次输入 # topv,topi = output_y.topk(1) # if topi.squeeze().item() == EOS_token: break input_y = topi.detach() # 4 其他 # 计算损失 # 梯度清零 # 反向传播 # 梯度更新 # 返回 损失列表myloss.item()/y_len -
代码实现
def train_iters(
x,
y,
my_encoderrnn: EncoderRNN,
my_attndecoderrnn: AttnDecoderRNN,
myadam_encode,
myadam_decode,
mynllloss,
total_steps,
current_step,
):
my_encoderrnn.train()
my_attndecoderrnn.train()
# 1 编码 encode_output, encode_hidden = my_encoderrnn(x, encode_hidden)
encode_hidden = my_encoderrnn.inithidden()
encode_output, encode_hidden = my_encoderrnn(x, encode_hidden) # 一次性送数据
# [1,6],[1,1,256] --> [1,6,256],[1,1,256]
# 2 解码参数准备和解码
# 解码参数1 encode_output_c [1, 10,256]
encode_output_c = torch.zeros(
1, MAX_LENGTH, my_encoderrnn.hidden_size, device=device
)
for idx in range(x.shape[1]):
encode_output_c[:, idx, :] = encode_output[:, idx, :]
# 解码参数2
decode_hidden = encode_hidden
# 解码参数3
input_y = torch.tensor([[SOS_token]], device=device)
myloss = 0.0
iters_num = 0
y_len = y.shape[1]
# 教师强制机制, 阈值线性衰减
teacher_forcing_ratio = max(0.1, 1 - (current_step / total_steps))
# 阈值指数衰减
# teacher_forcing_ratio = 0.9 ** current_step
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
for idx in range(y_len):
# 数据形状 [1,1],[1,1,256],[1,10,256] ---> [1,4345],[1,1,256],[1,1,10]
output_y, decode_hidden, attn_weight = my_attndecoderrnn(
input_y, decode_hidden, encode_output_c
)
target_y = y[:, idx]
myloss = myloss + mynllloss(output_y, target_y)
iters_num += 1
# 使用teacher_forcing
if use_teacher_forcing:
# 获取真实样本作为下一个输入
input_y = y[:, idx].reshape(shape=(-1, 1))
# 不使用teacher_forcing
else:
# 获取最大值的值和索引
topv, topi = output_y.topk(1)
if topi.item() == EOS_token:
break
# 获取预测y值作为下一个输入
input_y = topi.detach()
# 梯度清零
myadam_encode.zero_grad()
myadam_decode.zero_grad()
# 反向传播
myloss.backward()
# 梯度更新
myadam_encode.step()
myadam_decode.step()
# 计算迭代次数的平均损失
return myloss.item() / iters_num
6.3.4.3 构建模型训练函数¶
-
实现思路分析
Python# train_seq2seq() 思路分析 # 实例化 mypairsdataset对象 实例化 mydataloader # 实例化编码器 my_encoderrnn 实例化解码器 my_attndecoderrnn # 实例化编码器优化器 myadam_encode 实例化解码器优化器 myadam_decode # 实例化损失函数 mynllloss = nn.NLLLoss() # 定义模型训练的参数 # epoches mylr=1e4 teacher_forcing_ratio print_interval_num plot_interval_num (全局) # plot_loss_list = [] (返回) print_loss_total plot_loss_total starttime (每轮内部) # 外层for循环 控制轮数 for epoch_idx in range(1, 1+epochs): # 内层for循环 控制迭代次数 # for item, (x, y) in enumerate(mydataloader, start=1): # 调用内部训练函数 Train_Iters(x, y, my_encoderrnn, my_attndecoderrnn, myadam_encode, myadam_decode, mycrossentropyloss) # 计算辅助信息 # 计算打印屏幕间隔损失-每隔1000次 # 计算画图间隔损失-每隔100次 # 每个轮次保存模型 torch.save(my_encoderrnn.state_dict(), PATH1) # 所有轮次训练完毕 画损失图 plt.figure() .plot(plot_loss_list) .save('x.png') .show() -
代码实现
def train_seq2seq():
# 获取数据
(english_word2index, english_index2word, english_word_n,
french_word2index, french_index2word, french_word_n, my_pairs) = my_getdata()
# 实例化 mypairsdataset对象 实例化 mydataloader
mypairsdataset = MyPairsDataset(my_pairs, english_word2index, french_word2index)
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化编码器 my_encoderrnn 实例化解码器 my_attndecoderrnn
my_encoderrnn = EncoderRNN(english_word_n, 256).to(device)
my_attndecoderrnn = AttnDecoderRNN(output_size=french_word_n, hidden_size=256, dropout_p=0.1, max_length=10).to(
device)
# 实例化编码器优化器 myadam_encode 实例化解码器优化器 myadam_decode
myadam_encode = optim.Adam(my_encoderrnn.parameters(), lr=mylr)
myadam_decode = optim.Adam(my_attndecoderrnn.parameters(), lr=mylr)
# 实例化损失函数 mycrossentropyloss = nn.NLLLoss()
mynllloss = nn.NLLLoss()
# 定义模型训练的参数
plot_loss_list = []
# 统计所有轮次的总批次数
total_steps = epochs * len(mydataloader)
# 当前累计批次数
current_step = 0
# 外层for循环 控制轮数 for epoch_idx in range(1, epochs + 1):
for epoch_idx in range(1, epochs + 1):
print_loss_total, plot_loss_total = 0.0, 0.0
starttime = time.time()
# 内层for循环 控制迭代次数
# start=1: 下标从1开始, 默认0, 数据开始从第1个开始取
# item第1个值为1
for item, (x, y) in enumerate(mydataloader, start=1):
# 调用内部训练函数
myloss = train_iters(x, y, my_encoderrnn, my_attndecoderrnn, myadam_encode, myadam_decode, mynllloss, total_steps, current_step)
print_loss_total += myloss
plot_loss_total += myloss
# 累计训练批次数
current_step += 1
# 计算打印屏幕间隔损失-每隔1000次
if item % print_interval_num == 0:
print_loss_avg = print_loss_total / print_interval_num
# 将总损失归0
print_loss_total = 0
# 打印日志,日志内容分别是:训练耗时,当前迭代步,当前进度百分比,当前平均损失
print('轮次%d 损失%.6f 时间:%d' % (epoch_idx, print_loss_avg, time.time() - starttime))
# 计算画图间隔损失-每隔100次
if item % plot_interval_num == 0:
# 通过总损失除以间隔得到平均损失
plot_loss_avg = plot_loss_total / plot_interval_num
# 将平均损失添加plot_loss_list列表中
plot_loss_list.append(plot_loss_avg)
# 总损失归0
plot_loss_total = 0
# 每个轮次保存模型
torch.save(my_encoderrnn.state_dict(), 'model/my_encoderrnn_%d.pth' % epoch_idx)
torch.save(my_attndecoderrnn.state_dict(), 'model/my_attndecoderrnn_%d.pth' % epoch_idx)
# 所有轮次训练完毕 画损失图
plt.figure()
plt.plot(plot_loss_list.detach().numpy())
plt.savefig('img/s2sq_loss.png')
plt.show()
if __name__ == '__main__':
train_seq2seq()
输出结果:
轮次1 损失4.066723 时间:30
轮次1 损失3.645070 时间:62
轮次1 损失3.439869 时间:94
轮次1 损失3.255681 时间:125
轮次1 损失3.225276 时间:157
轮次1 损失3.192995 时间:188
轮次1 损失3.076638 时间:220
轮次1 损失3.005179 时间:252
轮次1 损失2.971412 时间:284
轮次1 损失2.921596 时间:318
...
6.3.4.4 损失曲线分析¶
损失下降曲线
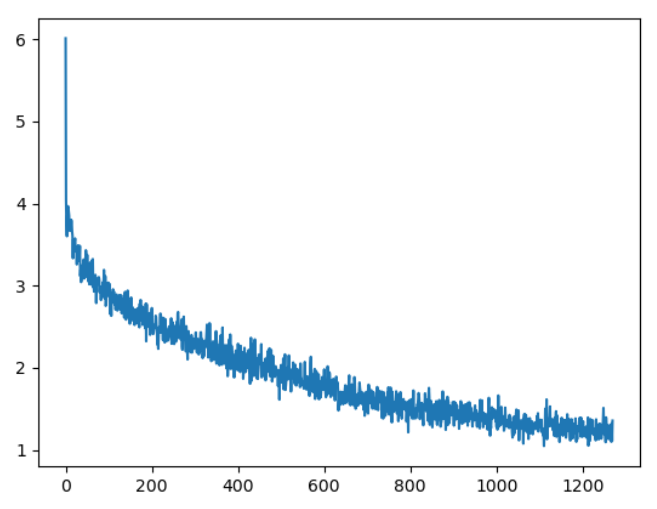
一直下降的损失曲线, 说明模型正在收敛, 能够从数据中找到一些规律应用于数据。
6.3.5 构建模型评估函数并测试¶
6.3.5.1 构建模型评估函数¶
# 模型评估代码与模型预测代码类似,需要注意使用with torch.no_grad()
# 模型预测时,第一个时间步使用SOS_token作为输入 后续时间步采用预测值作为输入,也就是自回归机制
def seq2seq_evaluate(
x, my_encoderrnn: EncoderRNN, my_attndecoderrnn: AttnDecoderRNN, french_index2word
):
with torch.no_grad():
my_encoderrnn.eval()
my_attndecoderrnn.eval()
# 1 编码:一次性的送数据
encode_hidden = my_encoderrnn.inithidden()
encode_output, encode_hidden = my_encoderrnn(x, encode_hidden)
# 2 解码参数准备
# 解码参数1 固定长度中间语义张量c
encoder_outputs_c = torch.zeros(
1, MAX_LENGTH, my_encoderrnn.hidden_size, device=device
)
x_len = x.shape[1]
for idx in range(x_len):
encoder_outputs_c[:, idx, :] = encode_output[:, idx, :]
# 解码参数2 最后1个隐藏层的输出 作为 解码器的第1个时间步隐藏层输入
decode_hidden = encode_hidden
# 解码参数3 解码器第一个时间步起始符
input_y = torch.tensor([[SOS_token]], device=device)
# 3 自回归方式解码
# 初始化预测的词汇列表
decoded_words = []
# 初始化attention张量
decoder_attentions = torch.zeros(1, MAX_LENGTH, MAX_LENGTH)
for idx in range(MAX_LENGTH): # note:MAX_LENGTH=10
output_y, decode_hidden, attn_weights = my_attndecoderrnn(
input_y, decode_hidden, encoder_outputs_c
)
# 预测值作为下一次时间步的输入值
topv, topi = output_y.topk(1)
decoder_attentions[:, idx, :] = attn_weights[:, 0, :]
# 如果输出值是终止符,则循环停止
if topi.item() == EOS_token:
decoded_words.append("<EOS>")
break
else:
decoded_words.append(french_index2word[topi.item()])
# 将本次预测的索引赋值给 input_y,进行下一个时间步预测
input_y = topi.detach()
# 返回结果decoded_words,注意力张量权重分布表(把没有用到的部分切掉)
# 句子长度最大是10, 长度不为10的句子的注意力张量其余位置为0, 去掉
return decoded_words, decoder_attentions[:, :idx + 1, :]
6.3.5.2 模型评估函数调用¶
PATH1 = "model/my_encoderrnn_2.pth"
PATH2 = "model/my_attndecoderrnn_2.pth"
def dm_test_seq2seq_evaluate():
(
english_word2index,
english_index2word,
english_word_n,
french_word2index,
french_index2word,
french_word_n,
my_pairs,
) = my_getdata()
# 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs, english_word2index, french_word2index)
# 实例化模型
input_size = english_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_encoderrnn = EncoderRNN(input_size, hidden_size).to(device)
"""
torch.load(map_location=)
map_location: 指定如何重映射模型权重的存储设备(如 GPU → CPU 或 GPU → 其他 GPU)。
# 加载到 CPU:map_location=torch.device('cpu') 或 map_location='cpu'。
自动选择可用设备:map_location=torch.device('cuda')。
自定义映射逻辑:通过函数定义设备映射规则。
map_location=lambda storage, loc: storage -> 该lambda函数直接返回原始存储对象(storage)
强制所有张量保留在保存时的设备上。当模型权重保存时的设备与当前环境一致时(例如均在CPU或同一GPU上),避免不必要的设备迁移。
load_state_dict(strict=)
strict:True(默认):要求加载的权重键(keys)与当前模型的键完全匹配。如果存在不匹配(例如权重中缺少某些键,或模型有额外键),抛出RuntimeError。
"""
my_encoderrnn.load_state_dict(
torch.load(PATH1, map_location=lambda storage, loc: storage), strict=False
)
print("my_encoderrnn模型结构--->", my_encoderrnn)
# 实例化模型
input_size = french_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_attndecoderrnn = AttnDecoderRNN(input_size, hidden_size).to(device)
# my_attndecoderrnn.load_state_dict(torch.load(PATH2))
my_attndecoderrnn.load_state_dict(
torch.load(PATH2, map_location=lambda storage, loc: storage), False
)
print("my_decoderrnn模型结构--->", my_attndecoderrnn)
my_samplepairs = [
[
"i m impressed with your french .",
"je suis impressionne par votre francais .",
],
["i m more than a friend .", "je suis plus qu une amie ."],
["she is beautiful like her mother .", "elle est belle comme sa mere ."],
]
print("my_samplepairs--->", len(my_samplepairs))
for index, pair in enumerate(my_samplepairs):
x = pair[0]
y = pair[1]
# 样本x 文本数值化
tmpx = [english_word2index[word] for word in x.split(" ")]
tmpx.append(EOS_token)
tensor_x = torch.tensor(tmpx, dtype=torch.long, device=device).view(1, -1)
# 模型预测
decoded_words, attentions = seq2seq_evaluate(
tensor_x, my_encoderrnn, my_attndecoderrnn, french_index2word
)
# print("attentions--->", attentions)
# print('decoded_words->', decoded_words)
output_sentence = " ".join(decoded_words)
print("\n")
print(">", x)
print("=", y)
print("<", output_sentence)
if __name__ == "__main__":
dm_test_seq2seq_evaluate()
输出结果:
> i m impressed with your french .
= je suis impressionne par votre francais .
< je suis impressionnee par votre francais . <EOS>
> i m more than a friend .
= je suis plus qu une amie .
< je suis plus qu une amie . <EOS>
> she is beautiful like her mother .
= elle est belle comme sa mere .
< elle est sa sa mere . <EOS>
6.3.5.3 Attention张量制图¶
def dm_test_Attention():
(
english_word2index,
english_index2word,
english_word_n,
french_word2index,
french_index2word,
french_word_n,
my_pairs,
) = my_getdata()
# 实例化dataset对象
mypairsdataset = MyPairsDataset(my_pairs, english_word2index, french_word2index)
# 实例化dataloader
mydataloader = DataLoader(dataset=mypairsdataset, batch_size=1, shuffle=True)
# 实例化模型
input_size = english_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_encoderrnn = EncoderRNN(input_size, hidden_size).to(device=device)
# my_encoderrnn.load_state_dict(torch.load(PATH1))
my_encoderrnn.load_state_dict(
torch.load(PATH1, map_location=lambda storage, loc: storage), False
)
# 实例化模型
input_size = french_word_n
hidden_size = 256 # 观察结果数据 可使用8
my_attndecoderrnn = AttnDecoderRNN(input_size, hidden_size).to(device=device)
# my_attndecoderrnn.load_state_dict(torch.load(PATH2))
my_attndecoderrnn.load_state_dict(
torch.load(PATH2, map_location=lambda storage, loc: storage), False
)
sentence = "we re both teachers ."
# 样本x 文本数值化
tmpx = [english_word2index[word] for word in sentence.split(" ")]
tmpx.append(EOS_token)
tensor_x = torch.tensor(tmpx, dtype=torch.long, device=device).view(1, -1)
# 模型预测
decoded_words, attentions = seq2seq_evaluate(
tensor_x, my_encoderrnn, my_attndecoderrnn, french_index2word
)
print("decoded_words->", decoded_words)
# print('\n')
# print('英文', sentence)
# print('法文', output_sentence)
# 创建热图
fig, ax = plt.subplots()
# cmap:指定一个颜色映射,将数据值映射到颜色
# viridis:从深紫色(低值)过渡到黄色(高值),具有良好的对比度和可读性
cax = ax.matshow(attentions[0].cpu().detach().numpy(), cmap="viridis")
# 添加颜色条
fig.colorbar(cax)
# 添加标签
for (i, j), value in np.ndenumerate(attentions[0].cpu().detach().numpy()):
ax.text(j, i, f"{value:.2f}", ha="center", va="center", color="white")
# 保存图像
plt.savefig("img/s2s_attn.png")
plt.show()
print("attentions.numpy()--->\n", attentions.numpy())
print("attentions.size--->", attentions.size())
if __name__ == "__main__":
dm_test_Attention()
输出结果:
Attention可视化:
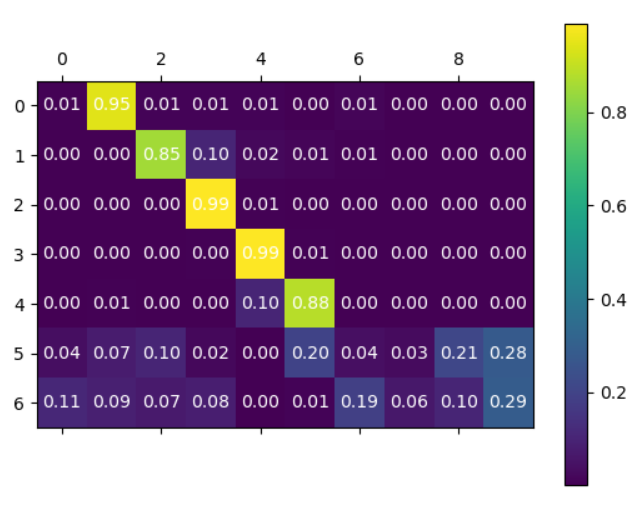
- Attention图像的纵坐标代表生成的目标语言各个词汇对应的索引, 0-6分别对应[“nous”, “sommes”, “toutes”, “deux”, “enseignantes”, “.”, “EOS”], 横坐标代表输入的源语言各个词汇对应的索引, 0-9代表[‘SOS’, ‘we’, ‘re’, ‘both’, ‘teachers’, ‘.’, ‘EOS’, ‘’, ‘’, ‘’], 图中浅色小方块(颜色越浅说明影响越大)代表词汇之间的影响关系, 比如源语言的第2个词汇对生成目标语言的第1个词汇影响最大, 源语言的第6个词对生成目标语言的第5, 6个词会影响最大, 通过这样的可视化图像, 我们可以知道Attention的效果好坏, 与我们人为去判定到底还有多大的差距. 进而衡量我们训练模型的可用性。
6.4 小结¶
- seq2seq模型架构
- seq2seq模型架构包括三部分,分别是encoder(编码器)、decoder(解码器)、中间语义张量c。其中编码器和解码器的内部实现都使用了GRU模型
- 基于GRU的seq2seq模型架构实现翻译的过程
- 第一步: 导入必备的工具包和工具函数
- 第二步: 对持久化文件中数据进行处理, 以满足模型训练要求
- 清洗文本和构建文本字典、构建数据源、构建数据迭代器。文本处理的本质就是根据任务构建标签x、标签y
- 第三步: 构建基于GRU的编码器和解码器
- 构建基于GRU的编码器
- 构建基于GRU的解码器
- 构建基于GRU和Attention的解码器
- 第四步: 构建模型训练函数, 并进行训练
- 什么是teacher_forcing: 它是一种用于序列生成任务的训练技巧, 在seq2seq架构中, 根据循环神经网络理论,解码器每次应该使用上一步的结果作为输入的一部分, 但是训练过程中,一旦上一步的结果是错误的,就会导致这种错误被累积,无法达到训练效果, 因此,我们需要一种机制改变上一步出错的情况,因为训练时我们是已知正确的输出应该是什么,因此可以强制将上一步结果设置成正确的输出, 这种方式就叫做teacher_forcing
- teacher_forcing的作用: 能够在训练的时候矫正模型的预测,避免在序列生成的过程中误差进一步放大. 另外, teacher_forcing能够极大的加快模型的收敛速度,令模型训练过程更快更平稳
- 构建训练函数train
- 调用训练函数并打印日志和制图
- 损失曲线分析: 一直下降的损失曲线, 说明模型正在收敛, 能够从数据中找到一些规律应用于数据
- 第五步: 构建模型评估函数, 并进行测试
- 构建模型评估函数evaluate
- 随机选择指定数量的数据进行评估