5 解码器部分实现¶
学习目标¶
- 了解解码器中各个组成部分的作用
- 掌握解码器中各个组成部分的实现过程
5.1 解码器层¶
5.1.1 介绍¶
-
概念
解码器层(Decoder Layer)是Transformer架构中的基本单元之一,每个解码器层负责处理目标序列并与编码器的输出交互,以生成目标序列中的每个词。
-
作用
根据编码器提供的上下文信息和已生成的输出序列,逐步预测下一个token的表示。每个解码器层都能够处理上一层的输出,并结合编码器的信息,逐步生成更符合目标的输出序列。
tips:为什么是逐步预测下一个token?transformer的核心任务是生成一个输出序列(如翻译、文本生成等)。输出序列的长度通常是未知的,且每个时间步的输出依赖于前一个时间步的输出。因此,解码器必须逐步生成序列:
- 逐步生成:解码器每次生成一个字符(或词),并将其作为下一个时间步的输入。
- 自回归特性:这种逐步生成的方式称为自回归(Auto-regressive),是序列生成任务的典型特性。
- 训练阶段:解码器的输入是真实的目标序列(Ground Truth),通过Teacher Forcing的方式逐时间步训练。
- 推理阶段:解码器没有真实的目标序列,只能依赖自己生成的输出作为下一个时间步的输入。
-
结构
一个解码器层主要包含以下三个子层,每个子层都包含残差连接和层归一化:
-
掩码多头自注意力机制(Masked Multi-Head Self-Attention):
-
与编码器中的自注意力类似,但加入了掩码机制,确保模型在生成每个token时,只能关注到该token之前的 token。
-
用于捕捉输出序列中已生成token之间的关系。
-
公式:\(\text{Masked Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + \text{Mask}\right)V\)
- \(Q\)、\(K\)、\(V\)分别是查询、键和值的矩阵。
- \(\text{Mask}\)是遮挡矩阵
- \(d_k\)是键的维度
-
-
多头编码器-解码器注意力机制 (Multi-Head Encoder-Decoder Attention):
-
解码器还需要关注编码器的输出,从而将编码器的语义信息融入到解码过程。
-
该注意力机制的Query(Q)来自解码器的上一层输出,Key(K)和Value(V)来自编码器的输出。
-
公式:\(\text{Cross Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V\)
-
-
前馈全连接网络 (Feed-Forward Network):
-
一个简单的全连接网络,包含两个线性变换层和一个非线性激活函数(通常是ReLU或GELU)。
-
用于对每个token的表示进行非线性变换,并提取更高级的特征。
-
这个网络独立地处理每个位置的表示。
-
公式:\(\text{FFN}(x) = \text{ReLU}(xW_1 + b_1)W_2 + b_2\)
- \(W_1\)、\(W_2\) 是权重矩阵。
- \(b_1\)、\(b_2\) 是偏置向量。
-
-
-
工作流程
-
输入:
- 每个解码器层的输入是上一层解码器层的输出,或者对于第一层解码器层来说,是输出嵌入向量加上位置编码向量(形状为
[batch_size, seq_len, d_model])。
- 每个解码器层的输入是上一层解码器层的输出,或者对于第一层解码器层来说,是输出嵌入向量加上位置编码向量(形状为
-
掩码多头自注意力:
- 将输入x传递给掩码多头自注意力层,得到输出:\(MaskedAttention(x)\)。
- 掩码多头自注意力层捕捉输出序列中已生成token之间的关系,并且通过掩码机制来保证了自回归性质。
- Q, K, V 三个矩阵都来自于解码器的输入x。
-
残差连接和层归一化 (第一部分):
- 将掩码多头自注意力的输入x与输出\(MaskedAttention(x)\) 相加,形成残差连接:
\(x + MaskedAttention(x)\)
- 对残差连接的结果进行层归一化,得到第一部分的输出:
\(LayerNorm(x + MaskedAttention(x))\)
-
多头编码器-解码器注意力:
- 将经过层归一化的输出作为Query(Q),将编码器的输出作为Key(K)和Value(V)传递给多头编码器-解码器注意力层,得到输出:
\(EncDecAttention(x, encoder\_output)\)
-
Q来自解码器,K,V来自编码器。
-
该层允许解码器关注编码器提供的上下文信息,将输入序列的信息融合到输出序列的生成过程中。
-
残差连接和层归一化(第二部分):
- 将多头编码器-解码器注意力的输入(即上一层输出)与输出 \(EncDecAttention(x, encoder\_output)\) 相加,形成残差连接:
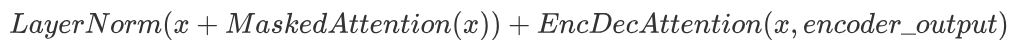
- 对残差连接的结果进行层归一化,得到第二部分的输出:
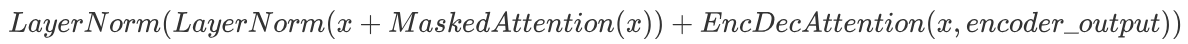
-
前馈全连接网络:
- 将经过残差连接和层归一化的输出传递给前馈全连接网络,得到输出:\(FFN(x)\)。
- 前馈全连接网络会对每个token的表示进行非线性变换,并提取更高级的特征。
-
残差连接和层归一化 (第三部分):
- 将前馈全连接网络的输入(即上一层输出)与输出\(FFN(x)\)相加,形成残差连接:
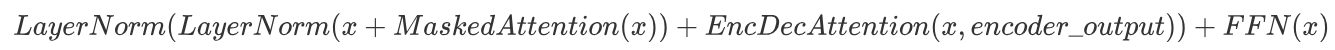
- 对残差连接的结果进行层归一化,得到第三部分的输出,也是解码器层的最终输出:
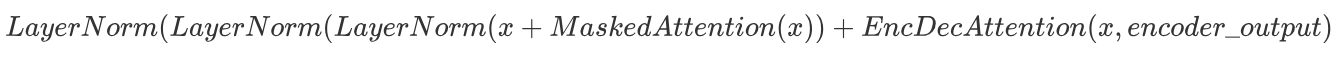
-
输出:
- 该层的输出会被传递给下一层解码器的输入(形状为
[batch_size, seq_len, d_model])。
- 该层的输出会被传递给下一层解码器的输入(形状为
-
5.1.2 代码实现¶
# 解码器层类 DecoderLayer 实现思路分析
# init函数 (self, size, self_attn, src_attn, feed_forward, dropout)
# 词嵌入维度尺寸大小size 自注意力机制层对象self_attn 一般注意力机制层对象src_attn 前馈全连接层对象feed_forward
# clones3子层连接结构 self.sublayer = clones(SublayerConnection(size,dropout_p),3)
# forward函数 (self, x, memory, source_mask, target_mask)
# 数据经过子层连接结构1 self.sublayer[0](x, lambda x:self.self_attn(x, x, x, target_mask))
# 数据经过子层连接结构2 self.sublayer[1](x, lambda x:self.src_attn(x, m, m, source_mask))
# 数据经过子层连接结构3 self.sublayer[2](x, self.feed_forward)
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout_p):
super(DecoderLayer, self).__init__()
# 词嵌入维度尺寸大小
self.size = size
# 自注意力机制层对象 q=k=v
self.self_attn = self_attn
# 一般注意力机制对象 q!=k=v
self.src_attn = src_attn
# 前馈全连接层对象
self.feed_forward = feed_forward
# clones3子层连接结构
self.sublayer = clones(SublayerConnection(self.size, dropout_p), 3)
def forward(self, x, memory, source_mask, target_mask):
m = memory
# 数据经过子层连接结构1
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))
# 数据经过子层连接结构2
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))
# 数据经过子层连接结构3
x = self.sublayer[2](x, self.feed_forward)
return x
函数调用:
def dm_test_DecoderLayer():
vocab = 1000 # 词表大小是1000
d_model = 512
# 输入x 形状是2 x 4
# 源数据与目标数据相同, 实际中并不相同
source = target = torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]])
my_embeddings = Embeddings(vocab, d_model)
embedded_result = my_embeddings(target) # [2, 4, 512]
dropout_p = 0.2 # 置0概率为0.2
max_len = 60 # 句子最大长度
my_pe = PositionalEncoding(d_model, dropout_p, max_len)
pe_result = my_pe(embedded_result)
# 类的实例化参数与解码器层类似, 相比多出了src_attn, 但是和self_attn是同一个类.
head = 8
d_ff = 64
size = 512
self_attn = src_attn = MultiHeadedAttention(head, d_model, dropout_p)
# 前馈全连接层也和之前相同
my_ff = PositionwiseFeedForward(d_model, d_ff, dropout_p)
# 产生编码器结果
# 注意此函数返回编码以后的结果 要有返回值, dm_test_Encoder函数后return en_result
en_result = dm_test_Encoder()
# 编码器-解码器多头注意力子层填充掩码
source_mask = (source != 0).type(torch.uint8).unsqueeze(1).unsqueeze(2)
# 解码器多头自注意力填充掩码
target_padding_mask = (target != 0).type(torch.uint8).unsqueeze(1).unsqueeze(2)
# 解码器多头自注意力因果掩码
target_causal_mask = torch.tril(torch.ones(size=(4, 4))).type(torch.uint8).unsqueeze(0).unsqueeze(0)
# 解码器多头自注意力子层掩码
target_mask = target_padding_mask & target_causal_mask
# 实例化解码器层 对象
my_dl = DecoderLayer(size, self_attn, src_attn, my_ff, dropout_p)
# 对象调用
dl_result = my_dl(pe_result, en_result, source_mask, target_mask)
print(dl_result.shape)
print(dl_result)
if __name__ == '__main__':
dm_test_DecoderLayer()
输出结果:
torch.Size([2, 4, 512])
tensor([[[ -4.0888, -0.3569, 19.7575, ..., -15.3458, -0.8096, 11.2497],
[ -4.9898, 48.7993, -11.4645, ..., 8.6564, 10.2307, -31.0148],
[ 26.7606, 47.9486, 33.0609, ..., -18.9295, 5.0897, 94.1305],
[ -0.3094, 10.9734, -25.9352, ..., 26.9372, -50.0279, -2.6424]],
[[-56.7436, 39.1334, 0.8712, ..., 0.8533, -14.4249, -19.0897],
[-50.5535, 56.5821, 50.2424, ..., 19.4151, 5.6403, -42.5772],
[ -0.3644, -45.2319, -5.3061, ..., 3.8075, 18.8357, 39.3184],
[ 57.7590, -3.2241, 12.3510, ..., -34.8855, -0.7769, -0.7925]]],
grad_fn=<AddBackward0>)
5.1.3 小结¶
- 什么是编码器层:
- 解码器层是Transformer架构中的基本单元之一,每个解码器层负责处理目标序列并与编码器的输出交互,以生成目标序列中的每个词。
- 解码器层的作用:
- 根据编码器提供的上下文信息和已生成的输出序列,逐步预测下一个token的表示。每个解码器层都能够处理上一层的输出,并结合编码器的信息,逐步生成更符合目标的输出序列。
- 实现解码器层的类: DecoderLayer
- 类的初始化函数的参数有5个, 分别是size,代表词嵌入的维度大小, 同时也代表解码器层的尺寸,第二个是self_attn,多头自注意力对象,也就是说这个注意力机制需要Q=K=V,第三个是src_attn,多头注意力对象,这里Q!=K=V,第四个是前馈全连接层对象,最后就是droupout置0比率。
- forward函数的参数有4个,分别是来自上一层的输入x,来自编码器层的语义存储变量mermory,以及源数据掩码张量和目标数据掩码张量。
- 最终输出了由编码器输入和目标数据一同作用的特征提取结果。
5.2 解码器¶
5.2.1 介绍¶
-
概念
解码器(Decoder)是Transformer模型的另一个核心组件,负责将编码器生成的特征表示转换为目标序列(如翻译后的句子或生成的文本)。解码器的设计类似于编码器,但增加了一些关键机制(如掩码自注意力)来适应序列生成任务。
解码器部分:
-
由N个解码器层堆叠而成
-
每个解码器层由三个子层连接结构组成
-
第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
-
第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
-
第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
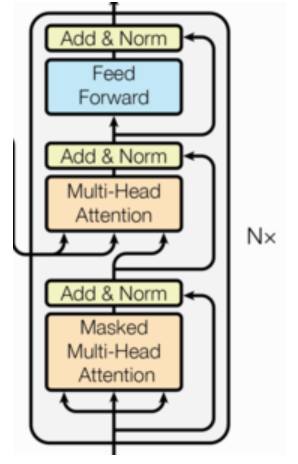
-
-
作用
- 特征解码:利用编码器生成的特征表示,逐步生成目标序列。
- 自回归生成:在生成目标序列时,解码器以自回归方式工作,即每次生成一个词,并将其作为下一步的输入。
- 捕捉上下文信息:通过自注意力机制和编码器-解码器注意力机制,捕捉目标序列和源序列之间的关系。
-
结构
解码器由多个相同的解码器层(Decoder Layer)堆叠而成。每个解码器层包含三个核心子层:
- 掩码多头自注意力机制(Masked Multi-Head Self-Attention):
- 计算目标序列中每个位置与之前位置的相关性。
- 通过掩码防止当前位置访问未来的信息。
- 编码器-解码器注意力机制(Encoder-Decoder Attention):
- 计算目标序列与源序列的相关性。
- 利用编码器的输出作为键和值。
- 前馈全连接层(Feed-Forward Neural Network, FFN):
- 对每个位置的表示进行非线性变换。
- 掩码多头自注意力机制(Masked Multi-Head Self-Attention):
-
工作流程
- 输入:
- 每个解码器层的输入是上一层的输出,或者对于第一层来说,是输出嵌入向量加上位置编码向量。
- 在训练时,输入是真实的输出序列(或者说“黄金标签”),而在推理时,输入是模型之前生成的输出序列。
- 掩码多头自注意力:
- 将输入传递给掩码多头自注意力层。
- 掩码机制确保了模型在预测某个token时,只能关注到它之前的token,而不能关注到它之后的token。这是为了保证解码的自回归性质。
- 残差连接和层归一化(第一部分):
- 将掩码多头自注意力的输入与输出相加,形成残差连接,然后进行层归一化操作。
- 多头编码器-解码器注意力:
- 将经过层归一化的输出作为Query(Q),将编码器的输出作为Key(K)和Value(V)传递给多头编码器-解码器注意力层。
- 这个子层允许解码器关注编码器提供的上下文信息,从而将输入序列的信息融入到输出序列的生成过程中。
- 残差连接和层归一化(第二部分):
- 将多头编码器-解码器注意力的输入与输出相加,形成残差连接,然后进行层归一化操作。
- 前馈全连接网络:
- 将经过层归一化的输出传递给前馈全连接网络,进行非线性变换和特征提取。
- 残差连接和层归一化(第三部分):
- 将前馈全连接网络的输入与输出相加,形成残差连接,然后进行层归一化操作。
- 输出:
- 每个解码器层的输出都会作为下一层解码器层的输入。
- 输入:
5.2.2 代码实现¶
# 解码器类 Decoder 实现思路分析
# init函数 (self, layer, N):
# self.layers clones N个解码器层clones(layer, N)
# self.norm 定义规范化层 LayerNorm(layer.size)
# forward函数 (self, x, memory, source_mask, target_mask)
# 数据以此经过各个子层 x = layer(x, memory, source_mask, target_mask)
# 返回处理好的数据
class Decoder(nn.Module):
def __init__(self, layer, N):
# 参数layer 解码器层对象
# 参数N 解码器层对象的个数
super(Decoder, self).__init__()
# clones N个解码器层
self.layers = clones(layer, N)
def forward(self, x, memory, source_mask, target_mask):
# 数据以此经过各个子层
for layer in self.layers:
x = layer(x, memory, source_mask, target_mask)
return x
函数调用:
# 测试 解码器
def dm_test_Decoder():
vocab = 1000 # 词表大小是1000
d_model = 512
# 输入x 形状是2 x 4
# 源数据与目标数据相同, 实际中并不相同
source = target = torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]])
my_embeddings = Embeddings(vocab, d_model)
embedded_result = my_embeddings(target) # [2, 4, 512]
dropout_p = 0.2 # 置0概率为0.2
max_len = 60 # 句子最大长度
my_pe = PositionalEncoding(d_model, dropout_p, max_len)
pe_result = my_pe(embedded_result)
# 分别是解码器层layer和解码器层的个数N
size = 512
d_model = 512
head = 8
d_ff = 64
dropout_p = 0.2
# 多头注意力对象
self_attn = src_attn = MultiHeadedAttention(head, d_model)
# 前馈全连接层
my_ff = PositionwiseFeedForward(d_model, d_ff, dropout_p)
# 产生编码器结果
en_result = dm_test_Encoder()
# 编码器-解码器多头注意力子层填充掩码
source_mask = (source != 0).type(torch.uint8).unsqueeze(1).unsqueeze(2)
# 解码器多头自注意力填充掩码
target_padding_mask = (target != 0).type(torch.uint8).unsqueeze(1).unsqueeze(2)
# 解码器多头自注意力因果掩码
target_causal_mask = torch.tril(torch.ones(size=(4, 4))).type(torch.uint8).unsqueeze(0).unsqueeze(0)
# 解码器多头自注意力子层掩码
target_mask = target_padding_mask & target_causal_mask
# 创建深拷贝函数
c = copy.deepcopy
# 解码器层
# c(attn):调用深拷贝函数对attn进行深拷贝
my_dl = DecoderLayer(size, c(self_attn), c(src_attn), c(my_ff), dropout_p)
N = 6
# 创建解码器对象
my_de = Decoder(my_dl, N)
# 解码器对象 解码
de_result = my_de(pe_result, en_result, source_mask, target_mask)
print(de_result)
print(de_result.shape)
if __name__ == '__main__':
dm_test_Decoder()
输出结果:
tensor([[[ 0.2676, -0.0462, -0.1605, ..., -1.9458, -0.0999, 0.1553],
[-0.7347, -0.7527, -1.8725, ..., -0.8728, 2.1724, -0.0156],
[ 0.8754, -0.0533, -0.0659, ..., 1.6729, -0.7587, 0.0440],
[ 0.0066, -0.0581, 1.2448, ..., 0.3517, 0.5180, -0.8565]],
[[-1.7937, 0.0469, 0.1267, ..., 0.7833, -0.2724, 0.0750],
[ 0.1900, -1.8415, -2.1007, ..., -0.2223, -1.8143, 0.6919],
[ 0.3878, -2.1848, -0.4604, ..., -0.3649, 0.6707, 0.1380],
[ 0.9642, 0.9571, -0.2017, ..., 0.8043, -0.1301, 0.1208]]],
grad_fn=<NativeLayerNormBackward0>)
torch.Size([2, 4, 512])
5.2.3 小结¶
- 什么是解码器:
- 解码器(Decoder)是Transformer模型的另一个核心组件,负责将编码器生成的特征表示转换为目标序列(如翻译后的句子或生成的文本)。解码器的设计类似于编码器,但增加了一些关键机制(如掩码自注意力)来适应序列生成任务。
- 解码器的作用:
- 特征解码:利用编码器生成的特征表示,逐步生成目标序列。
- 自回归生成:在生成目标序列时,解码器以自回归方式工作,即每次生成一个词,并将其作为下一步的输入。
- 捕捉上下文信息:通过自注意力机制和编码器-解码器注意力机制,捕捉目标序列和源序列之间的关系。
- 实现解码器的类: Decoder
- 类的初始化函数的参数有两个,第一个就是解码器层layer,第二个是解码器层的个数N。
- forward函数中的参数有4个,x代表目标数据的嵌入表示,memory是编码器层的输出,src_mask, tgt_mask代表源数据和目标数据的掩码张量。
- 输出解码过程的最终特征表示。