2 文本张量表示方法¶
学习目标¶
- 了解什么是文本张量表示及其作用
- 掌握文本张量表示的几种方法及其实现
2.1 文本张量表示¶
-
概念
将一段文本使用张量进行表示,其中一般将词汇表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示。
例如:
-
作用
将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作。
- 连接文本与计算机
- 机器可读性:计算机无法直接理解人类语言,文本张量表示是将文本转换为数值形式(通常是多维数组),使其能够被计算机处理和理解。
- 模型输入:大多数机器学习和深度学习模型(包括 NLP 模型)都需要数值输入,文本张量表示是文本数据进入这些模型的桥梁。
- 表达语义信息:
- 捕捉词语关系:好的文本张量表示方法,例如词嵌入,可以将词语映射到高维空间中,使得语义相似的词语在向量空间中也彼此接近。例如,“king” 和 “queen” 的向量在空间中会比 “king” 和 “apple” 更接近。
- 保留上下文信息:对于句子和文档的表示方法,例如句嵌入和文档嵌入,能够保留文本的上下文信息,例如词语之间的顺序和依赖关系。
- 理解文本含义:通过将文本映射到向量空间,模型可以学习到文本的深层语义含义,而不仅仅是表面上的字面意思。
- 提升模型性能:
- 特征提取:文本张量表示可以看作是对文本进行特征提取的过程,将文本转换为计算机可以理解的特征。
- 降维:一些文本张量表示方法,例如词嵌入,可以将文本的维度降低,减少模型的计算量,并避免维度灾难。
- 减少噪声:一些文本张量表示方法,例如 TF-IDF,可以对文本中的噪声进行过滤,突出重要信息。
- …
- 连接文本与计算机
-
文本张量表示的方法
- one-hot编码
- Word2vec
- Word Embedding
- …
2.2 0ne-Hot词向量表示¶
-
概念
one-hot编码是一种将离散的分类变量转化为二进制向量的方法。在自然语言处理中,one-hot编码常用于表示单词。每个单词都被表示为一个稀疏向量,该向量的长度等于词汇表的大小,其中只有一个位置为1,其他位置为0。
例如:
-
特点
- 稀疏性:one-hot编码通常会产生非常稀疏的向量,尤其是词汇表很大时。大部分元素为零,只有一个位置是1。
- 维度较高:词汇表的大小决定了one-hot向量的维度。如果词汇表包含10000个单词,那么每个单词的表示将是一个长度为10000的向量。
- 信息丢失:one-hot编码无法表达词与词之间的语义关系。例如,”cat” 和 “dog” 的表示完全不同,尽管它们在语义上很接近。
-
优缺点
- 优点:实现简单,容易理解。
- 缺点:高维稀疏向量,计算效率低,无法捕捉词之间的语义相似性。而且在大语料集下,每个向量的长度过大,占据大量内存。
-
one-hot编码器代码实现
Python# 导入keras中的词汇映射器Tokenizer from tensorflow.keras.preprocessing.text import Tokenizer # pip install tensorflow==2.12.1 -i https://mirrors.aliyun.com/pypi/simple/ # 导入用于对象保存与加载的joblib import joblib def dm_onehot(): # 1. 准备语料库。使用列表而非集合,以保证词汇处理顺序的确定性。 vocabs = ["周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"] # 2. 实例化Tokenizer并拟合语料库 # Tokenizer会自动构建词汇表,并将词语映射到从1开始的整数索引。 tokenizer = Tokenizer() tokenizer.fit_on_texts(texts=vocabs) print("词汇-索引 映射:", tokenizer.word_index) print("索引-词汇 映射:", tokenizer.index_word) # 3. 使用`texts_to_matrix`高效生成one-hot编码 # mode='binary'用于生成one-hot向量。 # Keras生成的矩阵第一列(索引0)是保留位,未使用。 # 通过切片[:, 1:]可以得到与原手动实现维度一致的结果。 one_hot_matrix = tokenizer.texts_to_matrix(vocabs, mode='binary')[:, 1:] print('one_hot_matrix--->', one_hot_matrix) print("--- One-Hot 编码 ---") for word, vector in zip(vocabs, one_hot_matrix): # 将numpy浮点数向量转为整数列表,方便查看 result = vector.astype(int).tolist() print(f"{word} 的one-hot编码是: {result}") # 4. 使用joblib保存Tokenizer对象,以便重用 tokenizer_path = './onehot_tokenizer.joblib' joblib.dump(tokenizer, tokenizer_path) # 5. 使用joblib加载Tokenizer对象,并生成"王力宏"的one-hot编码 print("--- One-Hot 编码 ---") tokenizer = joblib.load(tokenizer_path) result_ararry = tokenizer.texts_to_matrix(['王力宏'], mode='binary')[0, 1:] result_list = result_ararry.astype(int).tolist() print(f"'王力宏'的one-hot编码是: {result_list}") if __name__ == '__main__': dm_onehot()输出结果:
Python词汇-索引 映射: {'周杰伦': 1, '陈奕迅': 2, '王力宏': 3, '李宗盛': 4, '吴亦凡': 5, '鹿晗': 6} 索引-词汇 映射: {1: '周杰伦', 2: '陈奕迅', 3: '王力宏', 4: '李宗盛', 5: '吴亦凡', 6: '鹿晗'} one_hot_matrix---> [[1. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0.] [0. 0. 1. 0. 0. 0.] [0. 0. 0. 1. 0. 0.] [0. 0. 0. 0. 1. 0.] [0. 0. 0. 0. 0. 1.]] --- One-Hot 编码 --- 周杰伦 的one-hot编码是: [1, 0, 0, 0, 0, 0] 陈奕迅 的one-hot编码是: [0, 1, 0, 0, 0, 0] 王力宏 的one-hot编码是: [0, 0, 1, 0, 0, 0] 李宗盛 的one-hot编码是: [0, 0, 0, 1, 0, 0] 吴亦凡 的one-hot编码是: [0, 0, 0, 0, 1, 0] 鹿晗 的one-hot编码是: [0, 0, 0, 0, 0, 1] --- One-Hot 编码 --- '王力宏'的one-hot编码是: [0, 0, 1, 0, 0, 0]
2.3 Word2Vec模型¶
- Word2Vec概念
- Word2Vec是一种流行的将词汇表示成向量的无监督训练方法,该过程将构建神经网络模型,将网络参数作为词汇的向量表示,通过上下文信息来学习词语的分布式表示(即词向量)。它包含CBOW和skipgram两种训练模式。
- Word2Vec实际上利用了文本本身的信息来构建 “伪标签”。模型不是被人为地告知某个词语的正确词向量,而是通过上下文词语来预测中心词(CBOW)或者通过中心词来预测上下文词语(Skip-gram)。
- Word2Vec的目标是将每个词转换为一个固定长度的向量,这些向量能够捕捉词与词之间的语义关系。
- Word2Vec特点
- 密集表示:Word2Vec通过训练得到的词向量通常是稠密的,即大部分值不为零,每个向量的维度较小(通常几十到几百维)。
- 捕捉语义关系:Word2Vec可以通过词向量捕捉到词之间的语义相似性,例如通过向量运算可以发现”king”-“man”+”woman”≈”queen”。
- Word2Vec优缺点
- 优点:能够生成稠密的词向量,捕捉词与词之间的语义关系,计算效率高。
- 缺点:需要大量的语料来训练,且可能不适用于某些特定任务(例如:词语的多义性)。
2.3.1 CBOW(Continuous bag of words)模式¶
-
概念
给定一段用于训练的上下文词汇(周围词汇),预测目标词汇。
例如,在句子”the quick brown fox jumps over the lazy dog”中,如果目标词是”jumps”,则CBOW模型使用”the”,”quick”,”brown”,”fox”,”over”,”the”,”lazy”,”dog”这些上下文词来预测”jumps”。
图中窗口大小为9, 使用前后4个词汇对目标词汇进行预测。
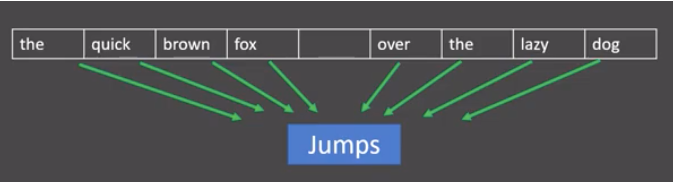
-
CBOW模式下的word2vec过程说明
-
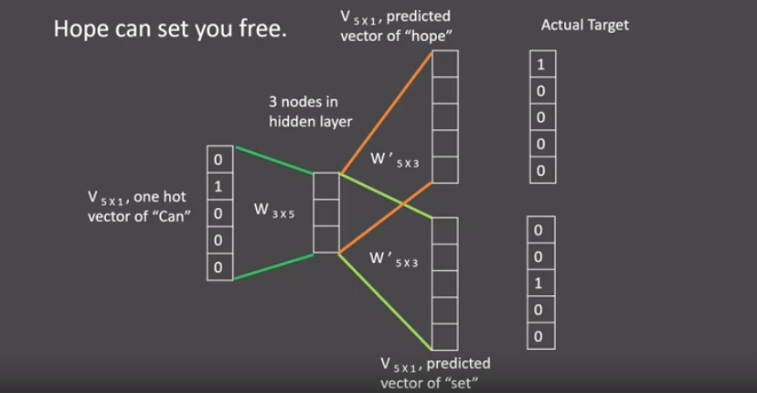
假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是CBOW模式,所以将使用Hope和set作为输入,can作为输出,在模型训练时,Hope,can,set等词汇都使用它们的one-hot编码。如图所示: 每个one-hot编码的单词与各自的变换矩阵(即参数矩阵3x5->随机初始化,这里的3是指最后得到的词向量维度)相乘,得到上下文表示矩阵(3x1),也就是词向量。将所有上下文词语的词向量按元素平均,得到平均词向量。
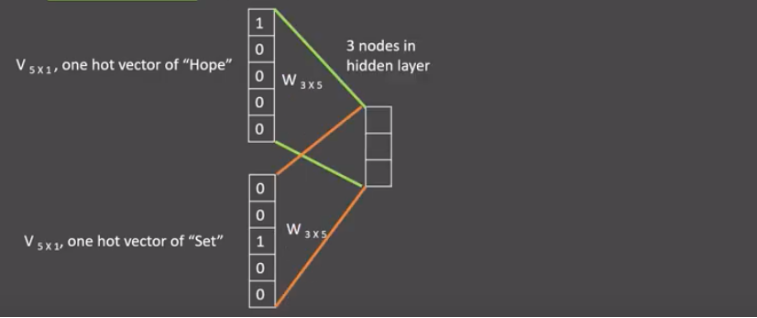
-
接着, 将上下文表示矩阵(平均词向量)与变换矩阵(参数矩阵5x3->随机初始化,所有的变换矩阵共享参数)相乘,得到5x1的结果矩阵,使用softmax函数将得分向量转换为概率分布,它将与我们真正的目标矩阵即can的one-hot编码矩阵(5x1)进行损失的计算,然后更新网络参数完成一次模型迭代。
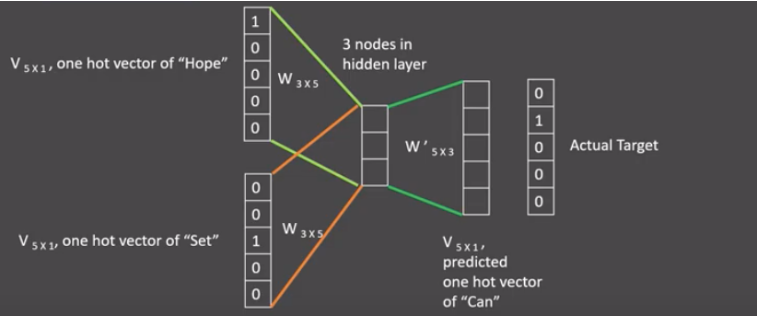
-
最后窗口按顺序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示。
-
2.3.2 Skip-gram模式¶
-
概念
给定一个目标词,预测其上下文词汇。
例如,在句子”the quick brown fox jumps over the lazy dog”中,如果目标词是”jumps”,skip-gram模型尝试预测它周围的词,如”the”,”quick”,”brown”,”fox”,”over”,”the”,”lazy”,”dog”。
图中窗口大小为9,使用目标词汇对前后四个词汇进行预测。
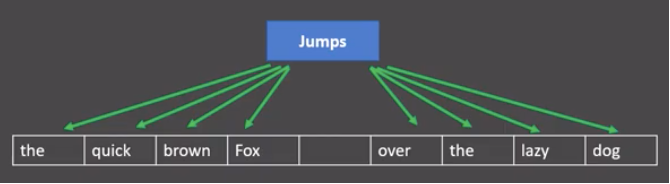
-
Skip-gram模式下的word2vec过程说明
-
假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope can set,因为是skip-gram模式,所以将使用can作为输入,Hope和set作为输出,在模型训练时,Hope、can、set等词汇都使用它们的one-hot编码。如图所示: 将can的one-hot编码与变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘, 得到目标词汇表示矩阵(3x1)。
-
接着, 将目标词汇表示矩阵与多个变换矩阵(参数矩阵5x3)相乘, 得到多个5x1的结果矩阵,使用softmax函数将得分向量转换为概率分布,它将与我们Hope和set对应的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模 型迭代。
-
最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵即参数矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示。
-
2.3.3 词向量的检索获取¶
-
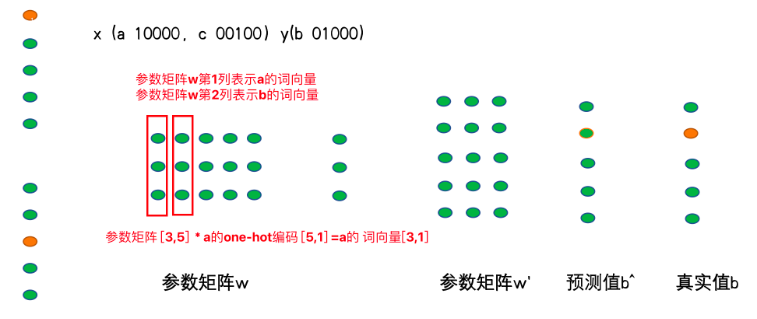
神经网络训练完毕后,神经网络的参数矩阵w就我们的想要词向量。如何检索某1个单词的向量呢?以CBOW方式举例说明如何检索a单词的词向量。
-
如下图所示:a的onehot编码[10000],用参数矩阵[3,5] * a的onehot编码[10000],可以把参数矩阵的第1列参数给取出来,这个[3,1]的值就是a的词向量。
2.4 词嵌入Word Embedding介绍¶
Word Embedding 与 Word2Vec 的关系
- Word2Vec是一种Word Embedding方法,专门用于生成词的稠密向量表示。Word2Vec通过神经网络训练,利用上下文信息将每个词表示为一个低维稠密向量。
- Word Embedding是一个更广泛的概念,指任何将词汇映射到低维空间的表示方法,不仅限于Word2Vec。GloVe和FastText等方法同样属于词嵌入。
-
概念
- 一种通过一定的方式将单词映射到指定维度的空间技术,目的是将单词的语义信息编码进低维向量空间。
- 广义的word embedding包括所有密集词汇向量的表示方法,如之前学习的word2vec, 即可认为是word embedding的一种。
- 狭义的word embedding是指在神经网络中加入的embedding层, 对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数), 这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵。
-
特点
- 低维稠密向量:词嵌入将每个词映射为低维稠密的向量,通常维度为50、100、200或300。
- 捕捉语义和句法信息:词嵌入能够捕捉词语之间的关系,例如语法上的相似性(如复数形式)和语义上的相似性(如”man”与”woman”)。
- 迁移学习:词嵌入能够在不同任务之间共享词向量,提高模型的泛化能力。
-
优缺点
- 优点:能够有效捕捉词的语义和句法信息,且训练出来的词向量可以在多个任务中使用。
- 缺点:对于一些低频词和未见过的词处理可能较差。
-
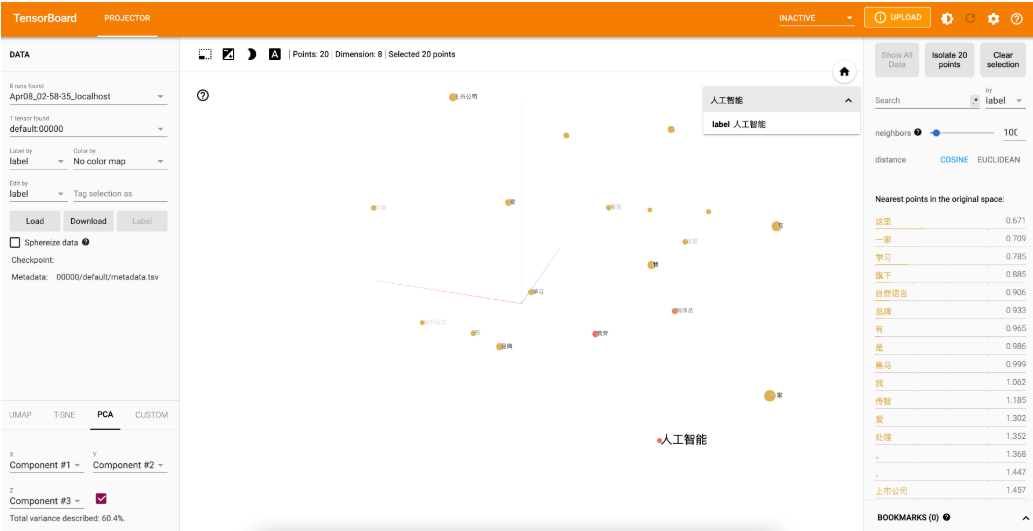
Word Embedding的可视化分析
通过使用tensorboard可视化嵌入的词向量
Pythonimport torch from tensorflow.keras.preprocessing.text import Tokenizer from torch.utils.tensorboard import SummaryWriter import jieba import torch.nn as nn # 实验:nn.Embedding层词向量可视化分析 # 1 对句子分词 word_list # 2 对句子word2id求my_token_list,对句子文本数值化sentence2id # 3 创建nn.Embedding层,查看每个token的词向量数据 # 4 创建SummaryWriter对象, 可视化词向量 # 词向量矩阵embd.weight.data 和 词向量单词列表my_token_list添加到SummaryWriter对象中 # summarywriter.add_embedding(embd.weight.data, my_token_list) # 5 通过tensorboard观察词向量相似性 # 6 也可通过程序,从nn.Embedding层中根据idx拿词向量 def dm02_nnembeding_show(): # 1 对句子分词 word_list sentence1 = '传智教育是一家上市公司,旗下有黑马程序员品牌。我是在黑马这里学习人工智能' sentence2 = "我爱自然语言处理" sentences = [sentence1, sentence2] word_list = [] for s in sentences: word_list.append(jieba.lcut(s)) # print('word_list--->', word_list) # 2 对句子word2id求my_token_list,对句子文本数值化sentence2id mytokenizer = Tokenizer() mytokenizer.fit_on_texts(texts=word_list) # print(mytokenizer.index_word, mytokenizer.word_index) # 打印my_token_list my_token_list = mytokenizer.index_word.values() print('my_token_list-->', my_token_list) # 打印文本数值化以后的句子 sentence2id = mytokenizer.texts_to_sequences(texts=word_list) print('sentence2id--->', sentence2id, len(sentence2id)) # 3 创建nn.Embedding层 embd = nn.Embedding(num_embeddings=len(my_token_list), embedding_dim=8) # print("embd--->", embd) # print('nn.Embedding层词向量矩阵-->', embd.weight.data, embd.weight.data.shape, type(embd.weight.data)) # 4 创建SummaryWriter对象 词向量矩阵embd.weight.data 和 词向量单词列表my_token_list # 词向量保存到runs目录中,不要出现中文路径,否则报错 # log_dir: 默认None, 保存到当前目录下的runs/xxx目录(自动创建)中 summarywriter = SummaryWriter(log_dir='D:/code/PycharmProjects/runs') # mat:词向量表示 张量或numpy数组 # metadata:词标签 summarywriter.add_embedding(mat=embd.weight.data, metadata=my_token_list) summarywriter.close() # 5 通过tensorboard观察词向量相似性 # cd 程序的当前目录下执行下面的命令 # 启动tensorboard服务 tensorboard --logdir=runs --host 0.0.0.0 # 通过浏览器,查看词向量可视化效果 http://127.0.0.1:6006 print('从nn.Embedding层中根据idx拿词向量') # # 6 从nn.Embedding层中根据idx拿词向量 for idx in range(len(mytokenizer.index_word)): tmpvec = embd(torch.tensor(idx)) print('%4s' % (mytokenizer.index_word[idx + 1]), tmpvec.detach().numpy())输出结果:
Pythonmy_token_list--> dict_values(['是', '黑马', '我', '传智', '教育', '一家', '上市公司', ',', '旗下', '有', '程序员', '品牌', '。', '在', '这里', '学习', '人工智能', '爱', '自然语言', '处理']) sentence2id---> [[4, 5, 1, 6, 7, 8, 9, 10, 2, 11, 12, 13, 3, 1, 14, 2, 15, 16, 17], [3, 18, 19, 20]] 2 从nn.Embedding层中根据idx拿词向量 是 [ 0.46067393 -0.9049023 -0.03143226 -0.32443136 0.03115687 -1.3352231 -0.08336695 -2.4732168 ] 黑马 [ 0.66760564 0.08703537 0.23735243 1.5896837 -1.8869231 0.22520915 -1.0676078 -0.7654686 ] 我 [-0.9093167 -0.6114051 -0.6825029 0.9269122 0.5208822 2.294128 -0.11160549 -0.34862307] 传智 [-1.1552105 -0.4274638 -0.8121502 -1.4969801 -1.3328248 -1.0934378 0.6707438 -1.1796173] 教育 [ 0.01580311 -1.1884228 0.59364647 1.5387698 -1.0822943 0.36760855 -0.4652998 -0.57378227] 一家 [-1.1898873 -0.42482868 -1.9391155 -1.5678993 -1.6960118 0.22525501 -1.0754168 0.41797593] 上市公司 [ 0.590556 2.4274144 1.6698223 -0.9776848 -0.6119061 0.4434897 -2.3726876 -0.2607738] , [-0.17568143 1.0074369 0.2571488 1.8940887 -0.5383494 0.65416646 0.63454026 0.6235991 ] 旗下 [ 2.8400452 -1.0096515 2.247107 0.30006626 -1.2687006 0.05855403 0.01199368 -0.6156502 ] 有 [ 0.89320636 -0.43819678 1.0345292 1.3546743 -1.4238662 -1.6994532 0.30445674 2.673923 ] 程序员 [ 1.2147354 0.24878891 0.36161897 0.37458655 -0.48264053 -0.0141514 1.2033817 0.7899459 ] 品牌 [ 0.59799325 -0.01371854 0.0628166 -1.4829391 0.39795023 -0.39259398 -0.60923046 0.54170054] 。 [ 0.59599686 1.6038656 -0.10832139 0.25223547 0.37193906 1.1944667 -0.91253406 0.6869221 ] 在 [-1.161504 2.6963246 -0.6087775 0.9399654 0.8480068 0.684357 0.96156543 -0.3541162 ] 这里 [ 0.1034054 -0.01949253 0.8989019 1.61057 -1.5983531 0.17945968 -0.17572908 -0.9724814 ] 学习 [-1.3899843 -1.0846052 -1.1301199 -0.4078141 0.40511298 0.6562911 0.9231357 -0.34704337] 人工智能 [-1.4966388 -1.0905199 1.001238 -0.75254333 -1.4210068 -1.854177 1.0471514 -0.27140012] 爱 [-1.5254552 0.6189947 1.2703396 -0.4826037 -1.4928672 0.8320283 1.7333516 0.16908517] 自然语言 [-0.3856235 -1.2193452 0.9991112 -1.5821775 0.45017946 -0.66064674 0.08045111 0.62901515] 处理 [ 1.5062869 1.3156213 -0.21295634 0.47610474 0.08946162 0.57107806 -1.0727187 0.16396333] 词向量和词显示标签 写入磁盘ok 在当前目录下查看 ./runs 目录在终端启动tensorboard服务:
Bash# 进入保存runs文件夹的目录路径下,执行以下shell命令 tensorboard --logdir=runs --host 0.0.0.0 # 通过http://127.0.0.1:6006访问浏览器可视化页面,打开网页后需再次刷新网页才能展示。浏览器展示并可以使用右侧近邻词汇功能检验效果:
2.5 小结¶
- 什么是文本张量表示:
- 将一段文本使用张量进行表示,其中一般将词汇为表示成向量,称作词向量,再由各个词向量按顺序组成矩阵形成文本表示.
- 文本张量表示的作用:
- 将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,进行接下来一系列的解析工作.
- 文本张量表示的方法:
- one-hot编码
- Word2vec
- Word Embedding
- 什么是one-hot词向量表示:
- 又称独热编码,将每个词表示成具有n个元素的向量,这个词向量中只有一个元素是1,其他元素都是0,不同词汇元素为0的位置不同,其中n的大小是整个语料中不同词汇的总数.
- one-hot编码的优劣势:
- 优势:操作简单,容易理解.
- 劣势:完全割裂了词与词之间的联系,而且在大语料集下,每个向量的长度过大,占据大量内存.
- 什么是word2vec:
- 是一种流行的将词汇表示成向量的无监督训练方法, 该过程将构建神经网络模型, 将网络参数作为词汇的向量表示, 它包含CBOW和skipgram两种训练模式.
- CBOW(Continuous bag of words)模式:
- 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用上下文词汇预测目标词汇.
- CBOW模式下的word2vec过程说明:
- 假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope you set,因为是CBOW模式,所以将使用Hope和set作为输入,you作为输出,在模型训练时, Hope,set,you等词汇都使用它们的one-hot编码. 如图所示: 每个one-hot编码的单词与各自的变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘之后再相加, 得到上下文表示矩阵(3x1).
- 接着, 将上下文表示矩阵与变换矩阵(参数矩阵5x3, 所有的变换矩阵共享参数)相乘, 得到5x1的结果矩阵, 它将与我们真正的目标矩阵即you的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模型迭代.
- 最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
- skipgram模式:
- 给定一段用于训练的文本语料, 再选定某段长度(窗口)作为研究对象, 使用目标词汇预测上下文词汇.
- skipgram模式下的word2vec过程说明:
- 假设我们给定的训练语料只有一句话: Hope can set you free (愿你自由成长),窗口大小为3,因此模型的第一个训练样本来自Hope you set,因为是skipgram模式,所以将使用you作为输入 ,hope和set作为输出,在模型训练时, Hope,set,you等词汇都使用它们的one-hot编码. 如图所示: 将you的one-hot编码与变换矩阵(即参数矩阵3x5, 这里的3是指最后得到的词向量维度)相乘, 得到目标词汇表示矩阵(3x1).
- 接着, 将目标词汇表示矩阵与多个变换矩阵(参数矩阵5x3)相乘, 得到多个5x1的结果矩阵, 它将与我们hope和set对应的one-hot编码矩阵(5x1)进行损失的计算, 然后更新网络参数完成一次模 型迭代.
- 最后窗口按序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵即参数矩阵(3x5),这个变换矩阵与每个词汇的one-hot编码(5x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示.
- 什么是word embedding(词嵌入):
- 通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间.
- 广义的word embedding包括所有密集词汇向量的表示方法,如之前学习的word2vec, 即可认为是word embedding的一种.
- 狭义的word embedding是指在神经网络中加入的embedding层, 对整个网络进行训练的同时产生的embedding矩阵(embedding层的参数), 这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵.