6 输出部分实现¶
学习目标¶
- 了解线性层和softmax的作用
- 掌握线性层和softmax的实现过程
6.1 输出层介绍¶
-
概念
输出层(Output layer)是模型最终生成目标序列的核心部分,它接收解码器的最后一层输出,并将其转换为目标词汇表中的具体词。
输出层通常由一个线性变换层 (Linear Layer)和一个Softmax层组成。
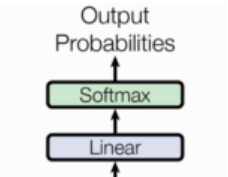
-
作用
- 特征映射:将解码器的输出(高维特征表示)映射到目标词汇表的大小。
- 概率分布:通过 Softmax 函数生成每个位置的目标词的概率分布。
- 序列生成:根据概率分布生成目标序列(如翻译后的句子或生成的文本)。
-
结构
- 线性变换层(Linear Layer):
- 也称为全连接层 (Fully Connected Layer)。
- 将解码器的输出从
d_model维度映射到tgt_vocab_size维度。 - 公式:\(logits=W⋅x+b\),其中 \(W\) 是权重矩阵,\(b\) 是偏置向量。
- Softmax层:
- 将线性变换的输出转换为概率分布。
- 对于每个词汇表中的token,Softmax函数会计算出一个概率值,表示模型预测这个token作为下一个输出的概率。
- 公式:\(probs=Softmax(logits)\)。
- 线性变换层(Linear Layer):
-
工作流程
- 解码器输出: 解码器最后一层的输出向量,通常是一个形状为 (batch_size, seq_len, d_model)的张量。
- 线性变换层: 解码器的输出向量会通过线性变换层,映射到一个新的向量空间,维度为tgt_vocab_size,输出的形状变为 (batch_size, seq_len, tgt_vocab_size)。
- Softmax函数: 线性变换层的输出会经过Softmax函数,将其转化为概率分布,输出的形状依然是 (batch_size, seq_len, tgt_vocab_size),其中每个值表示该位置预测为某个词汇表中token的概率。
- 选择预测结果:
- 训练: 在训练过程中,我们通常使用交叉熵损失函数来比较模型的预测概率分布与真实标签的分布,并更新模型的参数。
- 推理/预测: 在推理或预测时,我们会选择概率最高的token作为模型的预测输出。例如:可以使用argmax函数来选择概率最大的token的索引。
6.2 代码实现¶
Python
# 解码器类 Generator 实现思路分析
# init函数 (self, d_model, vocab_size)
# 定义线性层self.out
# forward函数 (self, x)
# 数据 torch.log_softmax(self.project(x), dim=-1)
class Generator(nn.Module):
def __init__(self, d_model, vocab_size):
# 参数d_model 线性层输入特征尺寸大小
# 参数vocab_size 线性层输出尺寸大小
super(Generator, self).__init__()
# 定义线性层
self.out = nn.Linear(d_model, vocab_size)
def forward(self, x):
# 数据经过线性层 最后一个维度归一化 log方式
x = torch.log_softmax(self.out(x), dim=-1)
return x
函数调用:
Python
if __name__ == '__main__':
# 实例化output层对象
# 解码器预测词的输出维度
d_model = 512
# 词汇表中词数量
vocab_size = 1000
my_generator = Generator(d_model, vocab_size)
# 准备模型数据
x = torch.randn(2, 4, 512)
# 数据经过out层
gen_result = my_generator(x)
print('gen_result--->', gen_result.shape, '\n', gen_result)
输出结果:
Python
gen_result---> torch.Size([2, 4, 1000])
tensor([[[-7.4949, -7.8329, -7.2474, ..., -6.6283, -7.0262, -7.1283],
[-7.4107, -6.8480, -6.7202, ..., -5.3701, -7.2082, -7.2225],
[-7.3881, -7.7449, -5.8400, ..., -6.8243, -7.1951, -6.4599],
[-7.3690, -6.8549, -7.4158, ..., -7.0073, -7.0981, -6.9379]],
[[-7.9115, -7.0295, -7.2436, ..., -7.5143, -6.7885, -6.8484],
[-6.9169, -7.1748, -6.4291, ..., -5.8896, -7.4494, -8.3578],
[-6.7564, -7.3401, -7.1291, ..., -6.4325, -6.7251, -5.9878],
[-6.5363, -7.7376, -7.5278, ..., -6.9457, -5.5249, -6.3223]]],
grad_fn=<LogSoftmaxBackward0>)
6.3 小结¶
- 什么是输出层:
- 模型最终生成目标序列的核心部分,它接收解码器的最后一层输出,并将其转换为目标词汇表中的具体词。
- 输出层作用:
- 特征映射:将解码器的输出(高维特征表示)映射到目标词汇表的大小。
- 概率分布:通过Softmax函数生成每个位置的目标词的概率分布。
- 序列生成:根据概率分布生成目标序列(如翻译后的句子或生成的文本)。
- 线性层作用:
- 将解码器的输出从
d_model维度映射到tgt_vocab_size维度。
- 将解码器的输出从
- softmax层作用:
- 将线性变换的输出转换为概率分布。
- 实现线性层和softmax层的类: Generator
- 初始化函数的输入参数有两个, d_model代表词嵌入维度, tgt_vocab_size代表词表大小。
- forward函数接受上一层的输出。
- 最终获得经过线性层和softmax层处理的结果。